Mastering Git Reset: Commit Alchemy
By Maxime Bréhin • Published on 11 May 2016
• 13 min
Cette page est également disponible en français.
The git reset command is a formidable tool unfortunately far too often misunderstood or poorly used. This is too bad, as it opens up a wide range of solutions and tips to optimize our work and workflows.
In order to best use git reset, you must understand its context. So this piece will start by revising a number of Git fundamentals. If you think you’re solid there, just scroll down to the “So what about Git reset?” heading. But I would advise you read through. You never know…
Resetting lets us tweak our version history and ongoing work. To do this, we must understand:
- how our history gets built;
- how Git handles our ongoing work;
- how that works gets archived in our history;
- what the mechanisms are to browse / traverse our branches and versions.
Fundamentals
SHA-1’s
In Git’s context, a SHA-1 is a technical reference for an object in the Git database. In reset’s context, we mostly care about commits. This is really just a checksum of the commit’s tree and other metadata. If you’re curious, Pro Git has a great section on this.
HEAD: “You are here”
HEAD is a pointer, a reference to our current position in terms of history. It states which commit we’re working on top of. It’s a bit like our shadow: it follows us everywhere we go!
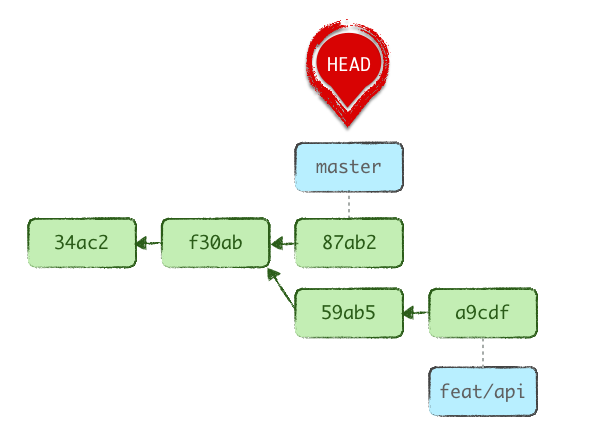
By default, HEAD references the current branch, e.g. master. But we can move it around to any reference or raw SHA-1. Technically it’s just a text file stored in .git/HEAD:
$ cat .git/HEAD
ref: refs/heads/masterIn turn, .git/refs/heads/master contains its tip commit’s SHA-1. Such a file then contains the commit’s metadata and tree information, which we can introspect using the plumbing command git cat-file:
$ git cat-file -p HEAD
tree 1d2cfad339094df7ecad1e40ed2d6382c97bbb35
parent 735371120ad60a15ad9d941a58b4f86deca8efa1
author Maxime Bréhin <maxime@delicious-insights.com> 1458209018 +0100
committer Maxime Bréhin <maxime@delicious-insights.com> 1458212547 +0100
Use d3 npm packageUsing git reset we move HEAD around as we see fit. Actually, whenever we have an active branch (which is by far the most common use case), the branch itself is repositioned, and HEAD just follows along.
A word about ORIG_HEAD
When you peeked into your .git directory, you might have seen a file named ORIG_HEAD. It’s related to HEAD, but always contains a raw SHA-1 instead of a named reference.
$ cat .git/ORIG_HEAD
e9090c653961d2cd8e91b02059931b8c8b5c0479ORIG_HEAD backs up the position of HEAD before a potentially dangerous operation (merge, rebase, etc.). This way, should things go awry, Git will be able to come back to the position before that by doing a git reset --keep ORIG_HEAD.
However, if you encounter an error with the --keep option, usually when there are conflicting files, you can try to use the --merge option instead. Be careful with this option though, because if you have indexed work that you want to keep, Git will scrap that work without asking for confirmation.
Areas
You probably already know that one of Git’s leading benefits is that your work is mostly local: a Git repo has its own local lifecycle, independent of its remote counterpart. This is great for performance, but not just for that.
This article focuses on that “local work.” As a complement to what we’re explaining here, we recommend this great interactive cheat sheet.
Git manages your work through 3 major local areas:
- Your working directory
- The index, or stage
- The (local) repository
There are two other areas (the stash, and the remote) but they’re largely irrelevant to the current discussion.
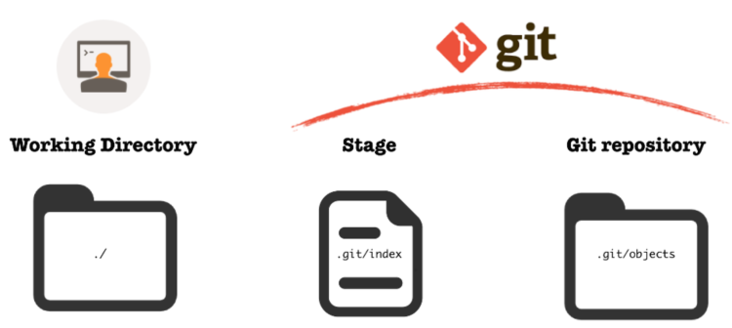
The working directory
It is the complete set of directories, subdirectories and files you’re working with for a particular project, at the root of which you normally have your .git directory, as a result of having called git init there.
The stage
This truly is the staging area for your next commit: this is where you put snapshots of whatever parts of your ongoing work you’re greenlighting for the next commit.
You add stuff to the stage through the git add command.
This area is known by many names: index (mostly in technical docs of Git), stage, staging area, staged files, cache (hence the legacy --cached options to commands such as git diff and git rm)… We favor stage.
The index name is most apparent in the name of the technical file that holds its current list of known files and trees: .git/index. You can see what’s in there in many ways, for instance through the plumbing command git ls-files --stage, which displays it as a tree (it is a tree, Git-wise):
$ git ls-files --stage
100644 48b9bcc9bd336a09a18c06cb1d4f10d6758e0116 0 .gitignore
100644 55ec243045a9ade2400f599f1a5e591b6c19ed7b 0 .tern-project
100644 96d3d35057c8a07b60b47f06e9d91ac82cdd088c 0 LICENSE
100644 664991ea874248f4232568b304608679dfa7db42 0 README.md
100644 0ed921b4648de073b19f827984a5b07f2226fd7d 0 package.json
…In short, the stage contains all necessary info for Git to create a commit, including a merge commit.
The (local) repository
This is all the metadata related to your versioned work: commits, references, local change history, configuration… It’s sort of like an archive room where everything you send is neatly compressed, labeled and stored in a way that makes retrieval as fast as possible whilst still optimizing storage.
Sending stuff in there is what git commit does.
You’re free to shuffle this around until you send a copy out to your remote repo, using git push. Even after that, you might want to tweak your local repo, but that’s not the point of this article.
Areas redux
Imagine your Git repo as a photo album.
The working directory is your camera, the venue you’re shooting at, your lighting and the subject of upcoming photos.
The stage is a list of snapshots you’re taking. Just like actual snapshots, you’re free to delete one and replace it with a better one. You’re snapshotting with git add.
Then you’re selecting some or all of your recent snapshots and carefully put them in a dedicated album page, adding date and comments as you go. That’s git commit for you.
Granted, this analogy only goes so far. But it should help give you a sense of what’s going on.

Where the heck am I?
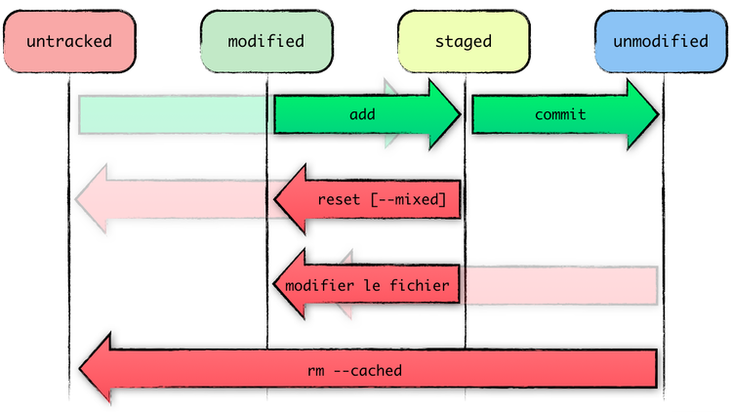
Besides this notion of areas, it’s interesting to look at the states Git assigns to files. If you think about it, working on a versioned set of files goes like this:
- You add files/work: “here comes new stuff I’ll version soon.”
- You greenlight it for your next commit: “this is definitely part of the topic I’ll make my next commit about.”
- You make a new version out of your list of greenlighted contents: “OK Git, take this particular stage and make a commit out of it.”
This maps to the following states:
- Unknown (brand new, unignored) files are untracked, and modified known files are modified;
- Greenlighted changes (snapshots) are staged;
- Files unchanged since the latest commit (HEAD) are unmodified.
Git “movement history”
We feel it’s important to stress that no porcelain command destroys a commit. At best, they create a new commit and rebuild history around it.
Obsolete commits are no longer part of your public history, but they still hang around the repo for quite a while, and there are two ways to access them again:
You jotted down or memorized their SHA-1 (good luck with that).
You browse the reflog to find them again.
Actual deletion of unreachable commits from the reflog will happen, by default, no earlier than 90 days after the commit happened, and only when Git gets around to garbage collecting.
So what about git reset?
Let’s now see what git reset brings to the table.
Do remember one thing: git reset is not just for one use case. We’ll try to illustrate here most of the common use cases you might encounter.
Getting our playground ready
Git goes out of its way to provide us with useful information about our ongoing work and state, whenever we do a git status. To see that, let’s first create an example repo and add two files to it:
mkdir git-reset-example
cd git-reset-example
git init
echo 'TODO' > README.md
echo 'tmp' > .gitignoreOur project is now set up, but Git hasn’t been told about any file yet. A git status will show that we have two untracked files:
$ git status
On branch master
Initial commit
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
README.mdSo let’s greenlight these files for the next (first) commit:
git add README.md .gitignoreA git status now tells us these changes are accounted for (“Changes to be committed”): they got staged in anticipation of our next commit. Because we’re in root commit state (there’s no commit yet, hence no HEAD), unstaging would require a git rm --cached instead of a git reset, and git status says as much:
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: .gitignore
new file: README.mdLet’s wrap up this first commit:
git commit -m "Initial commit"We can now add a new file with the current date:
date > date.txt
git add date.txtThis time git status does tell us that unstaging can be done via reset, as we’ll see in a second:
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: date.txtComing up!
- Fundamentals
- So what about
git reset? - OMG I so nuked my repo playing with
reset! git resetvsgit checkout: let the best one win!- One last word…
Unstaging stuff
We’ve just alluded, twice, to the fact that git reset is great for unstaging stuff you don’t eventually want in your next commit. For instance, we may have lazily typed a git add . and only then realized we hadn’t ignored a sensitive private key file such as private.key. Fear not, we can just unstage that file:
git reset private.shRemoving local changes from our WD
Sometimes we’ve started with local changes that end up being unsatisfactory, and we’d like to get back to the state we were at in the latest commit. This is what git reset --hard HEAD is for.
Caution: any local change to versioned files will be lost for good: be extra careful before you resort to this command. Only new, untracked files will be left alone, as HEAD didn’t know about them.
Let’s take our example repo again, and our freshly staged, new date.txt file. Let’s start by committing it:
git commit -m "Date file"Now let’s say we want to make a new commit with an extra timestamp in there. Unfortunately, we forget a > sign and replace the file instead of appending to it. No worries: just restore the previous commit, and start fresh.
date > date.txt # Argh!
git reset --hard # "Take me back to the latest commit"
date >> date.txt # That's more like itThe reset line implicitly targets HEAD (as many other Git commands when not provided with an explicit commit reference).
In such a situation though, hard resetting is like bulldozing through your WD, as it will undo every local change to every known file, not just the date file. You’ll probably be safer with a partial checkout, something git status also suggests:
git checkout HEAD date.txtThis lets us draw a series of paths from any given commit, and restore it in our WD and stage, without touching any other paths.
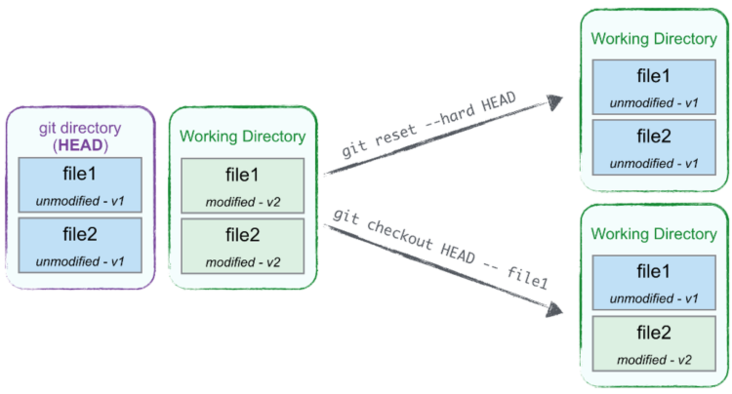
Undoing all or part of our latest commit
In the previous scenario, we had spotted the faulty staging before it went through and became a commit, but most of the time you’ll only notice it after the commit has happened. No worries, you just need to “undo” that commit and remove the culprit file from it, then “replay” the commit.
There are many ways to achieve this; the “100% reset” way brings the HEAD back one notch whilst preserving the stage and WD, then unstages all or part of our unwanted file.
# Let’s unwittingly add the private key too…
git add .
git commit -m "Adding the public key"
# Let’s now fix that!
git reset --soft HEAD~1
git reset private.sh
echo 'private.sh' >> .gitignore
git add .gitignore
git commit -m "Adding the public key"The fix goes like this:
- Bring the
HEADreference back one step (just theHEAD: neither the stage nor the WD). - Unstage
private.key. - Update
.gitignoreso this mishap can’t happen again, either to us or to our collaborators. - Commit again. This will use a different, current timestamping than the original one, which is no big deal as the original commit was strictly local so far anyway. Still, we could have gone with
git commit -C ORIG_HEADto re-use the metadata from the original commit, but that seemed overkill here. In practice though, you don’t do this soft reset then-Ccall by hand, you use the sweet--amendoption shortcut:
git reset HEAD~1 private.sh
echo 'private.sh' >> .gitignore
git add .gitignore
git commit --amend --no-editAugmenting our latest commit
There are really two subcases here:
- You forgot to add some files (a common culprit is resorting to
git commit -abut not realizing you’re also depending on new, untracked files that won’t get auto-added this way). - You want to tweak the commit message (those pesky typos…)
The former looks much like our previous situation: we want to get back to our previous stage, tweak it, then re-commit.
git reset --soft HEAD~1
# Stage the missing files
git commit -m "…"Again, --amend to the rescue, saving some keystrokes:
# Stage the missing files
git commit --amend --no-editIf instead you wish to change the message, just replace the --no-edit by a -m '…'. The only change being the message, there’s just one command line:
git commit --amend -m 'My typo-free commit message'Moving our X latest commits to their own branch
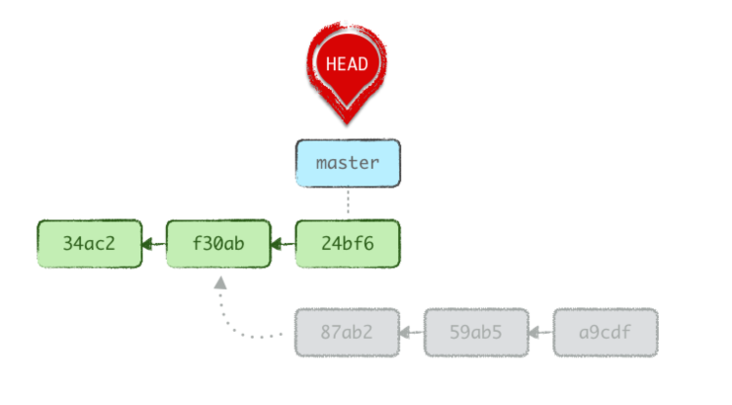
If you’re using Git properly, you do a lot of cheap branching. That is, you create a new branch for any unit of work, however quick and small, because Git makes branches easy, disk- and time-efficient, and splitting your work in neat pieces helps get into a better workflow.
Let’s say you haven’t always got that great reflex though, and you’ve been working on master for the past 3 commits instead of being on a topic branch (let’s call it feat/f1).
Fortunately, you realize this before mucking up the remote master branch with a git push.
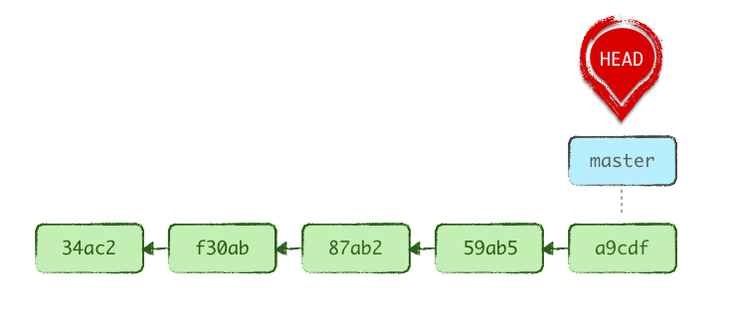
Fixing this is simple. Let’s first slap a branch label on top of the current commit, as we’re where our topic branch should be:
git branch feat/f1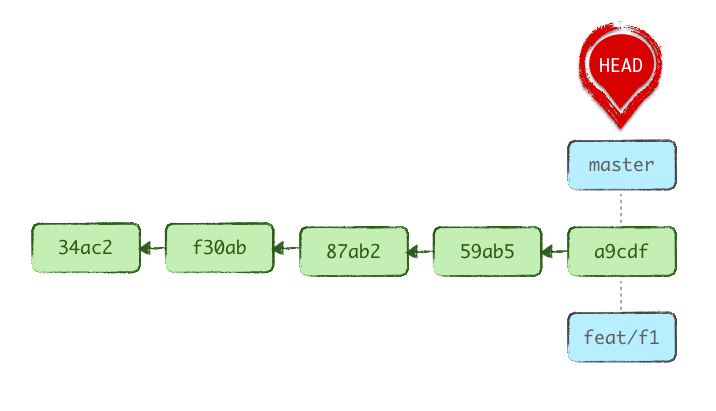
We then bring master back 3 steps. Any reset mode would do, but since we’re going to make feat/f1 the active branch in an instant, we might as well just move the HEAD around and leave the stage and WD intact.
git reset --soft HEAD~3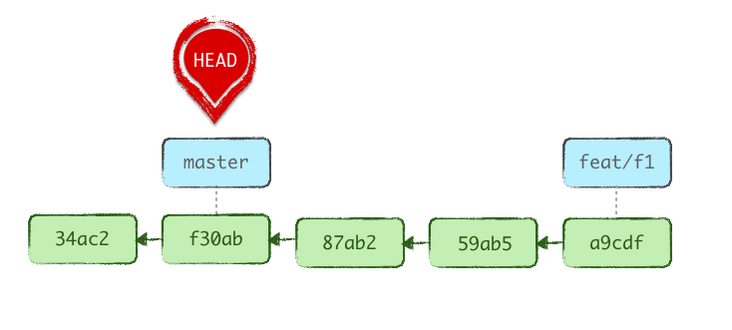
Finally, we make our branch active again, as our work isn’t quite done yet:
git checkout feat/f1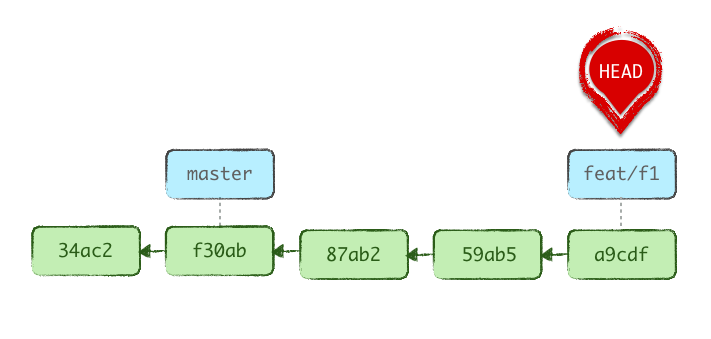
Killing our X latest commits
The previous scenario assumed these latest 3 commits were useful, and therefore branch-worthy. What if they were garbage? What if we were intoxicated?
We want these latest 3 commits off our history.
We can just hard reset three steps back, leaving these commits as unreachable references known only to our reflog, something Git will garbage collect in at least 90 days, but that will stay local anyway (not pushed).
git reset --keep HEAD~3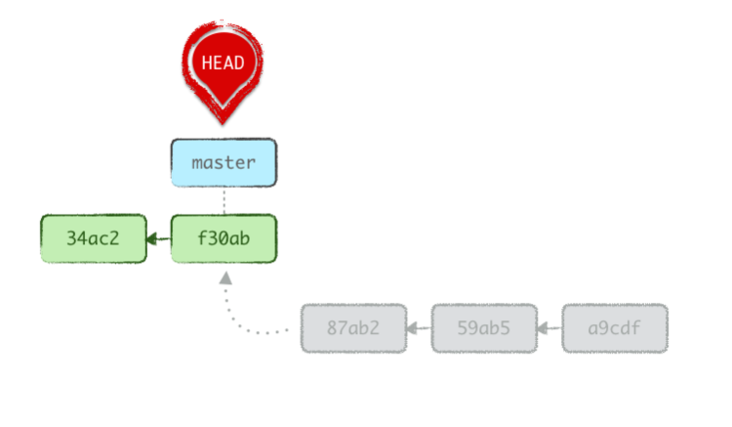
The next time we commit, we’ll move from the current origin, creating an alternative history that will then be the only public one.
Undoing our latest merge, rebase, cherry-pick…
So we did something that we shouldn’t have. We’re not proud. We want it to go away:
- we did a control merge; cool, but that needs to get off our history now.
- we did a
mergeorrebaseas the second step of apull, but eventually realized we didn’t want that work in our branch just yet. - we rebased on top of another branch, but unduly so (perhaps we inverted the direction of our rebase, for instance).
Fear not, as always: git reset to the rescue!
If you read through the Fundamentals part of this article, you may remember that nifty little backup ref Git maintains for us in many situations: ORIG_HEAD. It’s available for us in these situations. All we need to do is a merge-mode reset.
git reset --merge ORIG_HEADNow, the merge mode isn’t just for undoing merges. It’s sort of like a hard reset, except it will preserve any local changes we had going that didn’t prevent the operation from happening (for instance, we were editing files untouched by the merge). Better safe than sorry, you know.
OMG I so nuked my repo playing with reset!
Yeah. That happens. Reset is so cool, when you start learning about it, you’re resetting all over the place, like a wild puppy on steroids.
Have no fear. There’s really just one case where you’ll lose your work resetting: when you hard reset with local changes on known files. These latest changes (the ones since your latest commit) will get lost, because Git never got a chance to see them. That’s the reason why you should get rid of the --hard mode and prefer --keep instead: it will act the same when it comes to moving HEAD, but it will preserve your current changes (Working Directory and stage).
Anything else can be sorted out using the reflog.
This is a strictly local log that records every successive position of HEAD, regardless of the reason for its moving (it might even not end up moving, but the operation on it will get recorded all the same).
You can browse it with git reflog. It works in most ways just like git log, so you could look at the latest 8 positions of HEAD like so:
$ git reflog -7
2154788 HEAD@{0}: reset: moving to HEAD~3
15cc480 HEAD@{1}: checkout: moving from feat/f1 to master
3e221d0 HEAD@{2}: checkout: moving from master to feat/f1
15cc480 HEAD@{3}: commit: Pseudo commit n°2
d17c8d6 HEAD@{4}: commit (amend): Pseudo commit n°1
d17c8d6 HEAD@{5}: commit: Pseudo commit
3e221d0 HEAD@{6}: commit: Ajout date
2154788 HEAD@{7}: commit (initial): Initial commitThe first column lists the commit SHA-1 (abbreviated), the second is the reference form (zero being the most recent one, equivalent to just “HEAD”), and then you’ll get a rather detailed description of the command, or command step (think rebasing), responsible for the HEAD being tweaked.
You can easily get to any prior local position of your HEAD by just resetting to that position as listed in the reflog. For instance, for the previous one, even when ORIG_HEAD wasn’t properly set or updated:
git reset --keep HEAD@{1}Be careful, it’s not always the same as ORIG_HEAD. In a 10-commit rebasing, for instance, you’d likely have HEAD move 10 times, but ORIG_HEAD backs up the HEAD before the entire thing, so HEAD@{10}.
Also, a reset gets recorded in the reflog (as it tweaks the HEAD). Look at our reflog now:
$ git reset --keep HEAD@{1}
$ git reflog -3
15cc480 HEAD@{0}: reset: moving to @{1}
2154788 HEAD@{1}: reset: moving to HEAD~3
15cc480 HEAD@{2}: checkout: moving from feat/f1 to masterSo if you keep doing git reset --keep HEAD@{1}, you’ll circle around…
git reset vs git checkout: let the best one win!
Depending on what your need is, reset and checkout sometimes seem to achieve the same result, which could result in some confusion. Let’s try and sort it out.
Restoring a local file from some version
Only checkout lets you do that, through a partial checkout. It’s sort of like a path-specific hard reset, with the important additional distinction that it doesn’t move the HEAD at all.
# "Gimme feat/f1’s version of README.md"
git checkout feat/f1 -- README.md
# "Bring test/ and spec/ back 3 commits, keep the rest"
git checkout HEAD~3 -- test specHeads up!
When “moving” towards specific branches, it can be tempting to use git reset target-branch instead of git checkout target-branch. But there is a fundamental difference:
checkoutwill switch theHEADso it refers to the target branch, leaving your original branch untouched, and you end up with the target branch becoming the active one.resetwill move your current branch so it matches the target branch, “losing” any divergent commit line there might have been since their common ancestor. It doesn’t change the active branch.
Let’s start with a common base history:
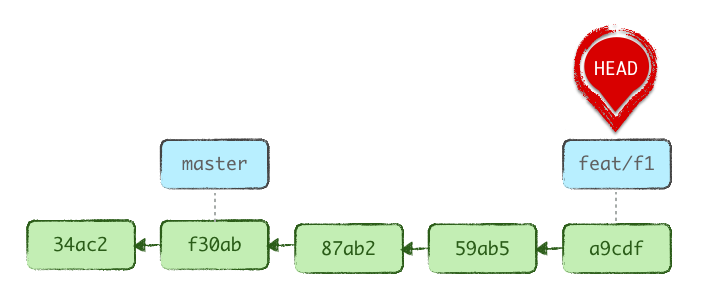
Checking out master switches HEAD to refer to it (the .git/HEAD file stops saying ref: refs/heads/feat/f1 and now says ref: refs/heads/master). We now have a different active branch, and feat/f1 is untouched.
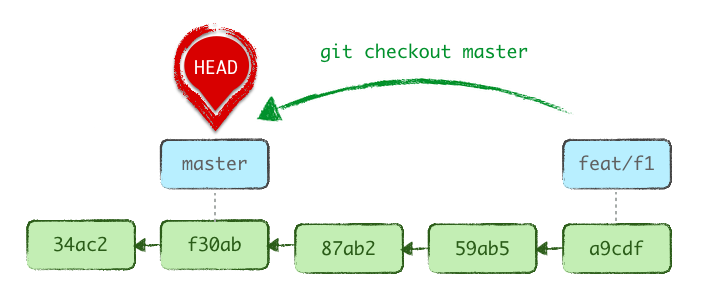
On the other hand, resetting HEAD to another branch keeps the current active branch (.git/HEAD is unchanged), but drags that branch label along to the target commit, effectively making the two branches identical.
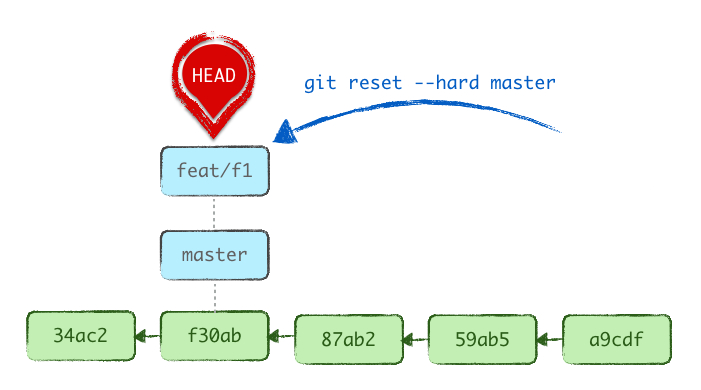
At first sight, it might seem to have worked, as you’re indeed seeing the contents of master in your WD, but you likely didn’t want to kill the specifics of your branch…
The analogy is far from perfect, but you may consider that:
resetis mostly about travelling in time, by going back and forth along the commit line of the current branch;checkoutis mostly about travelling in space, doing a side jump to other branches, or getting specific contents from them.
A word about the --keep option
The more doc-reading ones among you may know about the arcane --keep mode option for git reset. We intentionally left it alone, as its single valid use case is, in our opinion, best handled by judicious use of git stash.
One last word…
Rhinoceros.
More seriously, git reset is a fantastic Swiss-army knife that offers your remarkable flexibility in how you tweak your repo and local edits on a daily basis. Properly grokking its behavior will set you free of quite a few little artifical constraints, thereby increasing your productivity.
Combined with the reflog, it also offers a quasi-universal lifebuoy against mishaps, command accidents and the like, which should help you be more daring and bold when using Git :-)
Go forth, and reset!
P.S.: if you’d like to learn more about Git, you can check out our screencasts.