Une configuration Git aux petits oignons
Par Christophe Porteneuve • Publié le 3 avril 2013
• 11 min
This page is also available in English.
Git propose 3 niveaux de configuration :
- Locale. Spécifique à chaque dépôt local, elle est stockée dans le
.git/config. On y trouve notamment les trackings de branches, le remote, etc. - Globale. Spécifique à l’utilisateur, elle est stockée à la racine de son compte, dans le fichier
~/.gitconfig. C’est celle qui nous intéresse ici. - Système. Généralement stockée dans
/etc/gitconfig, elle est partagée par tous les utilisateurs. Elle est rarement employée.
Les priorités vont dans l’ordre usuel : du local au système.
La majorité des utilisateurs se contente de coller dans leur .gitconfig leur nom, e-mail et préférences d’éditeur. C’est là une sous-utilisation navrante. De très nombreux aspects quotidiens de Git sont paramétrables, et donc améliorables, au travers de la configuration.
Cet article explore ma configuration personnelle pour vous faire découvrir de nombreuses astuces utiles.
Avant toute chose, assurez-vous que vous utilisez un Git récent (2.22+). Plusieurs options de configuration évoquées ci-après n’ont fait leur apparition que récemment. Si une option semble ignorée chez vous, vérifiez soigneusement son nom et sa valeur, puis jetez un œil aux notes de version pour retrouver la version dans laquelle l’option est apparue.
Je maintiens une version publique générisée de ma configuration dans ce Gist. Par « générisée », je veux dire que j’en retire, ou que j’y commente, quelques traitements qui me semblent délicats à activer par défaut, car ils concernent des comportements subtils de Git qu’il vaut mieux bien connaître avant de les appliquer.
Un fichier de configuration Git est d’une syntaxe similaire à un bon vieux fichier INI : les sections sont délimitées par un en-tête [nom.section], et les lignes de propriété qui suivent appartiennent à la section. L’indentation est recommandée mais nullement obligatoire. La représentation linéarisée d’une propriété est section.nom, par exemple core.whitespace pour la propriété whitespace au sein de la section [core].
Voici déjà le gist global :
Examinons à présent les réglages un par un.
Identité par défaut pour les commits
C’est la base de la base : identifier vos commits à venir. On utilise pour cela user.name et user.email. Évitez toutefois de pourrir la config Git d’un utilisateur de déploiement sur un serveur de prod avec ce genre de trucs, si vous êtes plusieurs personnes à pouvoir déployer. Préférez qualifier un éventuel commit en prod (ouh là là…) avec git commit --author=… afin de ne pas vous mélanger les pinceaux.
Colorisation
De nombreuses commandes Git sont capables de coloriser leur affichage à l’aide de codes ANSI VT lorsque le terminal le permet. La valeur auto a le même sens que dans de nombreuses autres commandes Linux (par exemple ls) : Git détectera s’il est utilisé en direct par un terminal VT capable de gérer les codes de couleur, et si c’est le cas, exploitera cette possibilité.
La propriété color.ui est un paravent générique pour l’ensemble des propriétés plus spécifiques de gestion de couleur, par exemple color.branch, color.diff, color.grep, color.interactive, etc. En gros, on veut de la couleur !
Aliases
Git ne permet par défaut que les noms de commande complets (commit, checkout, etc.), ce qui fait parfois rager les Subversioniens débutant sur Git, qui cherchent en vain leur git ci. Outre qu’un prompt correctement configuré proposera une complétion avancée (ça fera l’objet d’un autre billet), la vraie raison est que Git permet de se créer autant d’aliases qu’on le désire, au moyen des réglages de la section [alias]. Chaque propriété a pour nom celui de l’alias et pour valeur la ligne de commande Git sans le git initial.
Ma configuration prévoit 3 aliases sans lesquels je ne saurais bosser :
cipour commitstpour statuslgpour un log textuel avancé qui, en ce qui me concerne, est tout-à-fait à la hauteur des logs graphiques (graphe de branches et fusions, références symboliques, tags et têtes de branches, SHAs, auteurs et horodatage relatif). Et le bonus, c’est qu’il marche dans un terminal, donc via SSH…
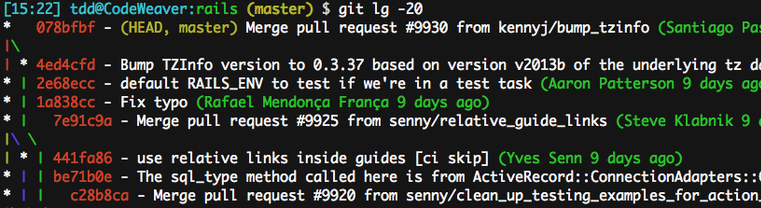
Pagination, whitespace et autres réglages « noyau »
Par défaut, Git pagine tout ce qu’il affiche : si ça dépasse la hauteur du terminal, ça se prend un less dans la figure. Personnellement, je ne supporte pas ça : si je veux paginer, je | less moi-même ! En spécifiant via core.pager de passer par cat plutôt que less, je désactive de facto la pagination.
Lorsqu’il ouvre un éditeur (notamment pour les messages de commit ou la mise en place d’un rebase interactif), Git choisit l’éditeur comme ceci :
- Variable d’environnement
GIT_EDITOR - Réglage
core.editor(c’est ce que je préfère) - Variable d’environnement
VISUAL - Variable d’environnement
EDITOR - Binaire par défaut retenu à la compilation de Git ; en général,
vi.
Si le comportement par défaut n’est pas votre tasse de thé, il vous faut spécifier la ligne de commande à exécuter. Lorsque l’éditeur est graphique, vous devrez l’invoquer de façon à ce qu’il soit en wait mode, c’est-à-dire qu’il ne rende la main qu’une fois le fichier fourni refermé. Tous les éditeurs graphiques n’ont pas cette possibilité.
Voici une liste de quelques lignes de commandes !
☝️ Si vous êtes sous Windows : si votre terminal ne reconnaît pas la commande d’ouverture de l’éditeur, vous devrez envisager de passer le chemin complet vers l’exécutable (ça dépend généralement du terminal utilisé).
- VSCode :
code -w - SublimeText :
subl -w. - GEdit :
gedit -w -s - GVim :
gvim --nofork - Coda : Il vous faut installer coda-cli (généralement via Homebrew, toujours aussi utile…) après quoi
coda -w. - Notepad++ : vous aurez peut-être besoin d’adapter le chemin en fonction de là où vous avez installé Notepad++, mais voici l’idée :
'C:/Program Files (x86)/Notepad++/notepad++.exe' -multiInst -notabbar -nosession -noPlugin.
Enfin, le réglage core.whitespace est là pour éviter que certains types de différences liées au whitespace ne soient détectés ou posent problème à des commandes comme git diff, git add -p, git apply ou git rebase. Il existe toute une série de valeurs possibles et combinables ; trailing-space est une combo pour blank-at-eol (whitespace en fin de ligne) et blank-at-eof (whitespace, notamment lignes vides, en fin de fichier). Comme j’indique ici cette valeur en négatif (notez le - préfixe), je précise que ce type d’écarts ne doit pas poser souci ni être signalé.
Diffs améliorés
Par défaut, toute forme de diff signale les deux versions comme a et b :
[15:54] tdd@CodeWeaver:git-attitude (master *+%) $ git diff 2013-04-03-configuration-git.markdown
diff --git a/source/_posts/2013-04-03-configuration-git.markdown b/source/_posts/2013-04-03-configuration-git.markdown
index e69de29..44bd5ae 100644
--- a/source/_posts/2013-04-03-configuration-git.markdown
+++ b/source/_posts/2013-04-03-configuration-git.markdownCe n’est pas toujours évident de savoir ce qu’est a et ce qu’est b… Le HEAD ? Le stage ? Le working directory ? Récemment, Git a fourni un réglage, diff.mnemonicPrefix, qui lorsqu’il est à true va remplacer, lorsque c’est possible, ces initiales anonymes par trois autres :
cpour Commit (généralement le HEAD)ipour Index (le stage)wpour Working directory
Ainsi, un diff classique explicite qu’il est effectué entre le stage (l’index) et le working directory :
[16:02] tdd@CodeWeaver:_posts (master *+) $ git diff 2013-04-03-configuration-git.markdown
diff --git i/source/_posts/2013-04-03-configuration-git.markdown w/source/_posts/2013-04-03-configuration-git.markdown
index 202f830..cde050e 100644
--- i/source/_posts/2013-04-03-configuration-git.markdown
+++ w/source/_posts/2013-04-03-configuration-git.markdownUn diff --staged indique bien qu’il est effectué entre le HEAD (un commit) et le stage (l’index) :
[16:02] tdd@CodeWeaver:_posts (master *+) $ git diff --staged 2013-04-03-configuration-git.markdown
diff --git c/source/_posts/2013-04-03-configuration-git.markdown i/source/_posts/2013-04-03-configuration-git.markdown
index cde050e..202f830 100644
--- c/source/_posts/2013-04-03-configuration-git.markdown
+++ i/source/_posts/2013-04-03-configuration-git.markdownQuant à un diff HEAD, qui explicite son commit de référence, il confirme qu’il compare un commit et le working directory :
[16:02] tdd@CodeWeaver:_posts (master *+) $ git diff HEAD 2013-04-03-configuration-git.markdown
diff --git c/source/_posts/2013-04-03-configuration-git.markdown w/source/_posts/2013-04-03-configuration-git.markdown
index cde050e..3f85496 100644
--- c/source/_posts/2013-04-03-configuration-git.markdown
+++ w/source/_posts/2013-04-03-configuration-git.markdownUn autre aspect un peu dommage de git diff est le comportement par défaut de git diff --word-diff. S’il est bien agréable d’avoir par défaut un mode word diff, qui permet de cibler, au sein de deux lignes sans doute très similaires, la zone de différence (un peu comme le changement de contraste dans des outils de diff graphiques), Git considère par défaut comme « mot » toute séquence de caractères non-whitespace. Dans un bloc de code, ça fait vite long, vu que les délimiteurs et opérateurs seront aussi comptabilisés. Par exemple, @twitterClient.directMessage(contact, est considéré comme un mot. Snif.
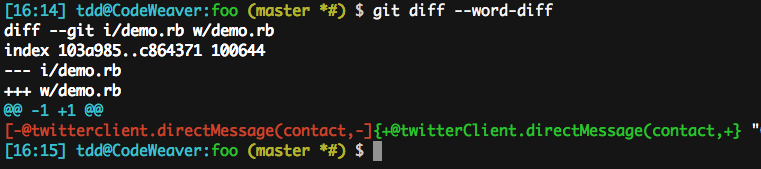
C’est pourquoi git diff fournit une autre option, --word-diff-regex=…, qui permet de préciser une regex représentant un « mot ». Naturellement, en réduisant cette regex à ., on va tenter la correspondance minimale (jusqu’à un seul caractère). Dans la pratique, quand je fais un diff de niveau mot, je fais toujours comme ça.
C’est là tout l’intérêt du réglage diff.wordRegex : il permet de traiter un simple --word-diff comme un --word-diff-regex=…. Voyez plutôt :
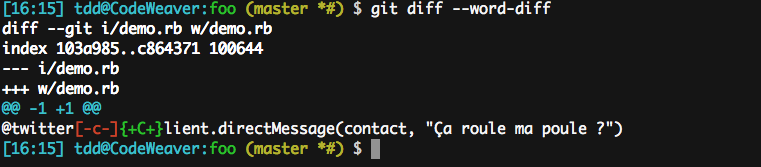
Submodules
Pour celles et ceux qui sont empêtrés dans les emmerdes quotidiennes des submodules (il y a des pièges à foison dans leur maintenance au quotidien), divers réglages permettent, au fil des versions, d’ajouter des garde-fous. J’en préconise quelques-uns :
fetch.recurseSubmodulesdétecte automatiquement lors d’unfetch(et donc d’unpull) si les références des submodules ont bougé, et propose de les récupérer automatiquement si c’est le cas. Attention, ça ne fait pas lesubmodule updatepour autant.status.submoduleSummaryprend soin de signaler dansgit statusles submodules dont la référence a bougé, en listant les deltas de commits concernés.
Regex étendues par défaut
Git propose à de nombreux endroits de recourir aux expressions rationnelles (regex). Notamment git log --grep et git log -G, pour ne citer qu’eux. Par défaut cependant, seules les BRE (Basic Regular Expressions) sont traitées, c’est-à-dire que la majorité des caractères spéciaux tels que {}, (), + et ? sont ignorés. Dans la pratique, quand j’utilise une regex, je veux toujours disposer de la syntaxe étendue (ERE, Extended Regular Expressions), qui active toutes les syntaxes possibles.
Plutôt que d’avoir alors à ajouter -E à ma ligne de commande, j’active le réglage grep.extendedRegexp dans la configuration globale.
Attention cependant : vos regex ne seront pas insensibles à la casse pour autant. Si vous voulez garantir cela, vous devrez généralement ajouter -i à vos lignes de commande.
Les SHA complets 🐈, ça ne sert à rien 😿
C’est un peu comme le H de Hawai.
La majorité des commandes de Git et de la documentation utilise des abbreviated SHA1s, ou abbrevs, soit les 7 premiers caractères seulement. La probabilité de collision de valeurs effectives à 7 caractères de SHA1 est infinitésimale (je ne suis pas expert, mais ça doit plafonner à 2−132, ce qui revient à dire que tu as à peine moins de chances de tomber sur un atome précis parmi tous ceux qui composent la Terre, nous inclus ; moi je dis, risque acceptable).
Histoire que même un bête git log sans options particulières se limite à ça, j’active log.abbrevCommit.
Des fusions plus pratiques
Si Git nous fournit effectivement pléthore de mécanismes afin de résoudre au mieux un conflit de fusion, il reste possible d’améliorer les comportements par défaut.
Ainsi, Git injecte dans les fichiers textuels des marqueurs de conflit classiques. Par exemple :
<body>
<<<<<<< HEAD
<h1>Super site de gros bills</h1>
=======
<h1>Super site de furieux</h1>
>>>>>>> feature
</body>Il est déjà possible d’obtenir davantage d’informations à ce stade, en affichant entre les deux (la branche récipiendaire de la fusion et la branche en cours de fusion) la version du texte dans l’ancêtre commun (le point de divergence, ou merge base). C’est le mode diff3, que j’active automatiquement avec le réglage merge.conflictStyle :
<body>
<<<<<<< HEAD
<h1>Super site de gros bills</h1>
||||||| merged common ancestors
<h1>Super site de déglingos</h1>
=======
<h1>Super site de furieux</h1>
>>>>>>> feature
</body>Par ailleurs, lorsqu’on recourt à un outil de résolution de conflits (un mergetool), celui-ci peut générer des fichiers temporaires ou de sauvegarde (souvent avec des extensions genre .rej, .orig, .local, .tmp, .bak…), qui viennent joyeusement pourrir votre working directory. Même si ces extensions sont protégées contre un ajout par inadvertance à l’aide d’un .gitignore ou équivalent, les fichiers restent là.
Vous pouvez vous assurer que votre outil va nettoyer derrière lui en désactivant les réglages mergetool.keepBackup et mergetool.keepTemporaries.
Pour finir sur les mergetools, lorsqu’on lance git mergetool, il demande par défaut confirmation quant au fichier à manipuler. Afin de vous éviter cette question le plus souvent superflue, désactivez mergetool.prompt.
Un autre sujet important, sur lequel nous avons également un article détaillé, est Rerere. Cette fonctionnalité avancée de Git permet d’enregistrer (localement) des empreintes de conflits et les résolutions manuelles que vous leur avez apportées, pour ré-utiliser automatiquement ces résolutions par la suite. C’est extrêmement pratique et permet des workflows très puissants. Je vous invite à aller explorer la doc à ce sujet, et si vous souhaitez vous en servir, vous n’aurez qu’à activer rerere.enabled et, si vous souhaitez mettre automatiquement dans le stage ces résolutions automatisées, rerere.autoupdate.
Des pulls en rebase par défaut
J’ai écrit un article détaillé sur les raisons pour lesquelles j’estime que l’immense majorité des pulls devraient utiliser un rebase plutôt qu’un merge. En gros, il s’agit d’éviter de pourrir l’historique quand on est à plusieurs à committer en même temps sur la même branche partagée.
La commande git pull est en fait une séquence de deux commandes plus spécifiques : git fetch suivie de git merge. Par exemple, si vous êtes sur master avec un remote par défaut origin, git pull revient à faire :
git fetchgit merge origin/master
Quand vous bossez à plusieurs sur la branche, il est le plus souvent préférable de faire l’équivalent de :
git fetchgit rebase origin/master
Git anticipe ce scénario et vous le permet avec git pull --rebase. Toutefois, il devrait s’agir à mon sens du cas général, et non du cas particulier. Il est en effet devenu possible de bosser ainsi en activant l’option pull.rebase.
Le seul danger potentiel, c’est qu’un rebase, par défaut, « inline » les fusions. C’est ajustable quand on git rebase manuellement, mais ça ne l’était longtemps pas dans le cadre d’un pull. Prenons un exemple.
Disons que vous venez de procéder à une fusion légitime sur votre branche locale (par exemple, la branche feature était terminée et vous avez procédé à son rapatriement sur master à l’aide d’un git merge feature).
Le push vous est refusé car il s’avère que le master distant (origin/master) a bougé. Pas le choix, vous faites un pull avant de continuer. Si celui-ci est en mode rebase, vous allez automatiquement rebaser l’historique local récent (les commits depuis votre ancienne référence origin/master, dont votre commit de fusion) sur le nouveau origin/master. En temps normal c’est top, mais sur ce coup ça va inliner la fusion en remplaçant le true merge par un rebase. La branche, jusqu’ici bien visible dans le graphe du log, va disparaître.
Heureusement, Git propose désormais une option étendue git pull --rebase=merges qu’on peut renseigner une fois pour toutes en configuration (pull.rebase = merges) et qui permettra de préserver les fusions locales lors du rebase (elles seront rejouées intégralement).
Des pushes plus ciblés
Par défaut, git push tente de publier toutes vos branches homonymes au remote. S’il m’arrive très rarement d’avoir de nouveaux travaux sur plusieurs branches en local qui soient trackées sur le remote, et donc d’avoir besoin de ça, il m’arrive en revanche régulièrement de tomber dans le scénario suivant :
- Je dois collaborer quelques temps à la branche
feature: jegit switch feature, ce qui cale une branche locale trackée sur la distante. - Je bosse, je committe, je pushe, tout roule…
- Au bout d’un moment, soit ça fait un bail que je ne bosse que sur
featureet monmasterprend du retard sur le distant, soit j’ai fini avecfeaturejusqu’à nouvel ordre, je repasse surmasteret au bout d’un moment mafeaturelocale est en retard sur la version distante.
À ce moment-là, chaque push va me taper dessus en rejetant la ou les branches en retard. C’est assez pénible, parce que je ne cherche pas en fait à pusher ces branches, je les ai juste en local et je rebosserai sans doute dessus plus tard. C’est le mode matching, qui comme le dit la doc n’est pas approprié à un environnement multi-développeurs, mais était (jusqu’à Git 2.0 en tout cas) le mode par défaut.
En réglant push.default à upstream, je change le comportement par défaut de push afin qu’il ne se préoccupe que de la branche active. C’est une variante plus flexible du mode simple, qui exigerait que les branches locale et distante soient non seulement connectées (tracking) mais homonymes. À noter que ce mode simple sera le mode par défaut à partir de Git 2.0.
En conclusion…
Bon, voilà une bonne chose de faite ! Pensez à jeter un œil aux notes de version quand vous mettez à jour votre Git, et surtout à regarder de temps en temps ce qu’on trouve dans git help config, qui liste tous les réglages proposés, ou simplement si le git help de votre commande en cours ne fournit pas une section CONFIGURATION sur la fin, qui cible les réglages associés. On y apprend toujours plein de choses…
Bonne config à tous !
Des astuces en veux-tu en voilà !
On a tout plein d’articles et de vidéos existants et encore beaucoup à venir. Pour ne rien manquer, tu devrais penser à t’abonner à notre newsletter, à notre chaîne YouTube, nous suivre sur Twitter et Mastodon ou encore mieux, à suivre notre formation du feu de dieu 🔥 : Git Total !