26 modules Node.js que j’utilise tout le temps
Par Christophe Porteneuve • Publié le 23 octobre 2014
• 16 min
Je suis comme vous, je reviens toujours à une petite boîte à outils essentielle, qui m’accompagne de projet en projet, chaque outil ayant maintes fois prouvé sa valeur. C’est notamment le cas pour les modules Node.js.
Je me suis dit que ça pouvait vous intéresser de savoir lesquels j’utilise.
Utilitaires généraux
Quelques modules utiles vraiment partout tout le temps.
underscore
Que je soie côté client ou serveur, si je suis en JavaScript, j’ai Underscore sous la main. Ça me simplifie trop l’algorithmique courante.
debug
Lorsqu’on souhaite gérer intelligemment ses messages de débogage, une plâtrée de console.debug ou même console.log n’est guère suffisante… Il est préférable de se caler sur les modules noyaux et conventions Node, et d’utiliser un flux de sortie contextualisé et sensible à la variable d’environnement DEBUG (les modules noyaux de Node utilisent NODE_DEBUG).
On crée un logger de debug contextualisé comme ceci :
var debug = require('debug')('myapp:mycontext')Après quoi on s’en sert comme d’un appel console.debug, avec les mêmes paramètres, par exemple :
debug('Booting %s', APP_NAME)
debug('Server ready on port %d', app.get('port'))Ce qui est important, c’est que cet affichage en console est subordonné à la présence d’une valeur appropriée dans la variable d’environnement DEBUG. Celle-ci peut contenir un nombre quelconque de motifs séparés par des espaces ou virgules. Ces motifs peuvent se terminer par une astérisque (*) pour servir de préfixe uniquement.

Remarquez la coloration (personnalisable à l’aide de codes prédéfinis), au passage, ainsi que les écarts, en millisecondes (ou en affichage complet UTC si la sortie standard n’est pas un TTY), entre les appels.
À présent que la mode est à l’utilisation de modules Node côté client (via des outils comme browserify, par exemple), sachez que debug marche aussi dans les consoles des navigateurs, coloration comprise !
colors
Puisqu’on parle de coloration, lorsqu’il s’agit de balancer des textes en couleurs quelque part (sorties standard ou d’erreur, fichiers texte…) je suis personnellement assez fan de colors. Le simple fait de requérir le module étend String.prototype avec des accesseurs enrobant la chaîne avec les codes VT256 nécessaires. On peut chaîner ces accesseurs, évidemment.
Outre les couleurs de texte (ex. red, green) et de fond (ex. bgWhite, bgBlue), on trouve les codes habituels d’altération (ex. bold, underline) et même quelques enrobages pour le moins fantaisistes tels que rainbow, america et trap.
require('colors')
console.log('Be careful!'.red)
console.log('YAY, working!'.green.underline)
console.log('Do NOT miss this'.bgGreen.white.bold)
console.log('Rainbow Dash is awesome'.rainbow)
console.log('Captain Rogers to The Rescue'.america)
console.log('Drop That Bass'.trap)
console.log('Drop That Bass'.trap)
console.log('Drop That Bass'.trap)
console.log('Drop That Bass'.trap)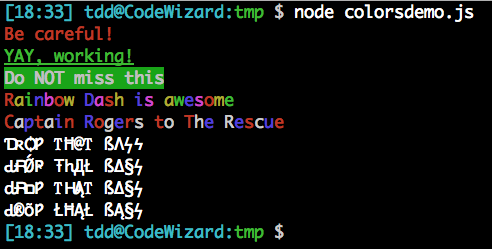
Un autre module est encore plus populaire : chalk. Certes, il est très puissant, mais la plupart du temps je n’ai pas besoin de ses avantages, et l’approche de colors me parle davantage. Après, chacun ses goûts (et ses besoins)…
mkdirp, rimraf et cpr
L’API du module noyau fs laisse à désirer dès qu’on souhaite travailler récursivement : les opérations mkdir, unlink et copy, notamment, ne prévoient pas ce cas. Évidemment, npm a très vite vu apparaître des modules qui prennent ça en charge.
C’est pratique quand on n’a par ailleurs aucun besoin riche sur les I/O et le filesystem, mais si vous utilisez par ailleurs une merveille comme q-io/fs (voir plus bas), vous aurez déjà accès à l’équivalent, en version basée promesses qui plus est, ce qui est toujours mieux.
Promesses, I/O et flux
Les promesses, c’est le bien. Et les I/O comme les flux méritent souvent une surcouche à leur API native.
rsvp
Je suis un fan absolu des promesses (et vous devriez, vous aussi). Il existe un bon paquet de modules sur npm pour travailler avec, notamment q, rsvp et bluebird.
En théorie, ce dernier est le plus rapide, mais on parle ici de différences extrêmements faibles, et tant que je n’aurai pas besoin de tenir la charge de PayPal ou Walmart, ça ne m’inquiète pas plus que ça.
En revanche, j’ai l’œil fixé sur ES6, qui a nativement les promesses, avec son type Promise. Et il se trouve que dans cette optique, rsvp m’intéresse parce que, de tous les modules de promesses, il est celui dont l’API colle au plus près à celle d’ES6. En fait, quand je suis en ES6, tout ce que j’ai à faire c’est de retirer cette ligne en haut de mon code :
var Promise = require('rsvp').PromiseÉvidemment, ce côté future-proof m’intéresse. Et les performances restent excellentes. Et puis de toutes façons, comme tous ces modules collent à la spec Promises/A+, ils sont interopérables dans la joie (entre eux, mais aussi avec les promesses natives ES6, évidemment), ce qui est juste parfait.
Énormément de gens traitent leurs besoins de workflows asynchrones avec async, et ce module est certes intéressant et sympathique, mais pratiquement tous ces besoins sont couverts, et de façon infiniment plus lisible et maintenable, à coup de promesses…
q-io
Dès qu’on a goûté aux promesses, on ne peut plus s’en passer, et on veut notamment s’en servir dès qu’on fait de l’I/O. Ça concerne notamment :
- L’accès au système de fichiers (ce qu’on ferait normalement par le module noyau
fs) - Les sockets (modules noyaux
netethttp, notamment)
Les modules noyaux, et de nombreux modules tiers, restent sur une approche à base de callbacks Node, c’est à dire des fonctions de rappel dont le premier argument est une éventuelle erreur, et les suivants les valeurs en cas de succès.
Tout ça est un foutoir à composer/chaîner, d’où l’émergence de modules ultra-populaires comme async, évoqué plus haut.
Côté promesses, on trouve des modules « ciblés » (ex. promised-fs), mais j’aime énormément q-io, qui fournit en un seul module des enrobages basés promesses pour tout ce que je fais habituellement en I/O en tant que « client » :
- Le requêtage HTTP (ou même le serveur, mais là je m’en fous un peu) avec
q-io/http(que je ferais, autrement, avec le module tiersrequest) - Les accès filesystem avec
q-io/fs(qui va bien au-delà de l’équivalent du module noyaufs)
Parmi les trucs que j’adore particulièrement :
copyTree, qui m’évite d’avoir à installer un module genrecpr,makeTree, qui m’évite le très courant module tiersmkdirp,removeTree, qui m’évite le tout aussi courantrimraf…split,join,normal, etc. qui n’ont pas besoin des promesses en tant que tels mais m’évitent souvent de devoir recourir au module noyaupath, d’ailleurs parfois moins pratique, en complément de monq-io/fs. En fait on trouve une tonne de méthodes avancées de manipulation de chemins, parfois très pratiques.- Le MockFS, qui fournit une API identique mais sur un filesystem virtuel, facile à initialise, très pratique pour les tests unitaires.
read, pour le requêtage HTTP, encore plus pratique que le module tiersrequest.
var FS = require('q-io/fs')
var HTTP = require('q-io/http')
FS.makeTree('/tmp/foo/bar/baz').then(function () {
console.log('Path created!')
})
HTTP.read(
'http://www.myapifilms.com/imdb?name=Julianne+Moore&filmography=1'
).then(function (data) {
var movies = _.findWhere(data.filmographies, { section: 'Actress' })
movies = _.map(movies, function (m) {
return m.title + ' (' + m.year + ')'
})
console.log(movies)
})Encore une fois, on peut mixer rsvp, pour coller au plus près de la future syntaxe ES6, et les promesses renvoyées par q-io (issues de q, mais interopérables puisque tout ce petit monde respecte Promises/A+). Que du bonheur.
event-stream
Si vous avez un besoin très ciblé, vous aurez sans doute plutôt recours à des modules tiers n’implémentant que le type de flux qui vous intéresse (genre concat-stream, split ou through, par exemple).
Personnellement j’ai souvent besoin de plusieurs types de flux avancés, aussi j’ai tendance à intégrer directement event-stream, qui me fournit la totale, agissant comme une sorte de meta-module par-dessus ceux plus ciblés :
split()pour une découpe ligne-à-ligne,mappour un transformateur générique,join,mergeetreplacepour des cas courants,parsepour interpréter du JSON au fil de l’eau (super utile sur des flux ou très gros fichiers),stringifyqui fait l’inverse : il produit un flux JSON à partir d’un flux d’objets ;- et quelques autres, plus techniques.
Supposons par exemple le flux JSON suivant :
{"title":"Don Jon","year":2013}
{"title":"Crazy, Stupid, Love.","year":2011}On pourrait le traiter comme ceci :
var es = require('event-stream')
var inspect = require('util').inspect
process.stdin
.pipe(es.split())
.pipe(es.parse())
.pipe(es.mapSync(inspect))
.pipe(process.stdout)Et ça nous donnerait un truc de ce genre :
{ title: 'Don Jon', year: 2013 }{ title: 'Crazy, Stupid, Love.', year: 2011 }
Configuration et CLI
Mes projets Node ont souvent besoin de configuration, persistante ou non, et d’options de ligne de commande pour leur personnalisation.
nconf
Dès que j’ai un projet basé CLI qui nécessite une configuration persistante, je sors nconf. Ce module fournit une gestion priorisée de config qui prend automatiquement en compte plusieurs sources, par priorité croissante :
- Des valeurs par défaut
- Un fichier de config libre (ou carrément un serveur Redis !)
- Les variables d’environnement
- Les options en ligne de commande
- …et même un objet/hash en mémoire !
- Des valeurs fixes, non modifiables, définies dans le code (overrides)
En fait, on peut même changer les priorités entre les valeurs par défaut et les valeurs fixes : le reste est utilisé dans l’ordre défini par notre code. Par exemple, pour l’ordre ci-dessus, ça ressemblerait à ça :
var nconf = require('nconf')
nconf
.argv()
.env()
.file({ file: path.join(__dirname, 'demo-config.json') })
console.log(nconf.get('foo'))
console.log(nconf.get('NODE_ENV'))
console.log(nconf.get('database:host'))Supposons que demo-config.json contienne :
{
"database": { "host": "localhost", "port": 7890 }
}On aurait les résultats suivants :
$ NODE_ENV=production node demo-config.js --foo youpi
youpi
production
localhost
$ node demo-config.js --foo bar --database:host 127.0.0.1
bar
undefined
127.0.0.1
On peut aussi s’en servir pour sauver l’état courant de la configuration sur disque, etc. Vraiment super pratique.
commander, nopt et optimist
Une fois n’est pas coutûme, je ne vais pas vous prescrire un choix parmi plusieurs, parce qu’ici, on touche vraiment à une question d’esthétique de code personnelle.
Ce sont les trois principaux modules dédiés à l’analyse des options en ligne de commande. Fonctionnellement, ils se valent peu ou prou. En termes de popularité, les lignes bougent un peu (nopt a récemment dépassé optimist, notamment, et commander reste le leader incontesté) mais on parle toujours de modules téléchargés au moins 3,5 millions de fois par mois…
Au final, c’est surtout le feeling de leur API qui décidera de votre choix. Lorsque j’ai des besoins qui calent bien dans le comportement par défaut d’optimist, je passe par lui pour me fader le moins de code possible. Le reste du temps je prends commander, mais je n’ai remarqué nopt que récemment et sa popularité croissante, son API très claire (et pas plus verbeuse que celle de commander) et son intense activité de maintenance/dev me font de l’œil.
Les philosophies divergent entre optimist d’un côté, qui essaie de vous épargner une configuration de CLI le plus souvent possible (mais vous laisse la faire si vous en avez vraiment besoin) et les deux autres, qui requièrent une config d’analyse.
Par exemple, avec optimist, on pourrait se contenter de :
var argv = require('optimist').argv
console.log('(%d,%d)', argv.x, argv.y)
console.log(argv._)$ node demo-optimist.js foo -x 0.54 bar -y 1.12 baz
(0.54,1.12)
[ 'foo', 'bar', 'baz' ]On peut naturellement configurer plus avant des banners, valeurs par défaut, aliases longs, types (booléens, etc.), argument requis, etc.
Chez nopt, on a un format de config assez bien fichu, assez clair, j’aime bien. C’est surtout utile quand tu veux être très strict sur les valeurs et types des options. Leur doc officielle illustre bien le principe :
// my-program.js
var nopt = require('nopt'),
Stream = require('stream').Stream,
path = require('path'),
knownOpts = {
foo: [String, null],
bar: [Stream, Number],
baz: path,
bloo: ['big', 'medium', 'small'],
flag: Boolean,
pick: Boolean,
many: [String, Array],
},
shortHands = {
foofoo: ['--foo', 'Mr. Foo'],
b7: ['--bar', '7'],
m: ['--bloo', 'medium'],
p: ['--pick'],
f: ['--flag'],
},
// everything is optional.
// knownOpts and shorthands default to {}
// arg list defaults to process.argv
// slice defaults to 2
parsed = nopt(knownOpts, shortHands, process.argv, 2)
console.log(parsed)$ node my-program.js --foo "blerp" --no-flag
{ "foo" : "blerp", "flag" : false }
$ node my-program.js ---bar 7 --foo "Mr. Hand" --flag
{ bar: 7, foo: "Mr. Hand", flag: true }
$ node my-program.js --foo "blerp" -f -----p
{ foo: "blerp", flag: true, pick: true }
$ node my-program.js -fp --foofoo
{ foo: "Mr. Foo", flag: true, pick: true }
$ node my-program.js --foofoo -- -fp # -- stops the flag parsing.
{ foo: "Mr. Foo", argv: { remain: ["-fp"] } }
$ node my-program.js --blatzk -fp # unknown opts are ok.
{ blatzk: true, flag: true, pick: true }
$ node my-program.js --blatzk=1000 -fp # but you need to use = if they have a value
{ blatzk: 1000, flag: true, pick: true }
$ node my-program.js --no-blatzk -fp # unless they start with "no-"
{ blatzk: false, flag: true, pick: true }
$ node my-program.js --baz b/a/z # known paths are resolved.
{ baz: "/Users/isaacs/b/a/z" }
# if Array is one of the types, then it can take many
# values, and will always be an array. The other types provided
# specify what types are allowed in the list.
$ node my-program.js --many 1 --many null --many foo
{ many: ["1", "null", "foo"] }
$ node my-program.js --many foo
{ many: ["foo"] }Et ce bon vieux commander a une API qui peut sembler plus compacte, tout en restant bien descriptive :
var program = require('commander')
program
.version('0.0.1')
.option('-p, --peppers', 'Add peppers')
.option('-P, --pineapple', 'Add pineapple')
.option('-b, --bbq', 'Add bbq sauce')
.option(
'-c, --cheese [type]',
'Add the specified type of cheese [marble]',
'marble'
)
.parse(process.argv)
console.log('you ordered a pizza with:')
if (program.peppers) console.log(' - peppers')
if (program.pineapple) console.log(' - pineapple')
if (program.bbq) console.log(' - bbq')
console.log(' - %s cheese', program.cheese)$ node commanderdemo.js
you ordered a pizza with:
- marble cheese
$ node commanderdemo.js -p --pineapple -c gorgonzola
you ordered a pizza with:
- peppers
- pineapple
- gorgonzola cheese
$ node commanderdemo.js --help
Usage: commanderdemo [options]
Options:
-h, --help output usage information
-V, --version output the version number
-p, --peppers Add peppers
-P, --pineapple Add pineapple
-b, --bbq Add bbq sauce
-c, --cheese [type] Add the specified type of cheese [marble]Il permet naturellement les coercions de type, une aide (banner) personnalisée, etc. Quand j’ai envie de restrictions nettes sur ma CLI, je quitte optimist pour aller chez commander.
NoSQL
Dans l’univers Node comme dans de plus en plus d’autres écosystèmes, on stocke de plus en plus dans des datastores NoSQL.
mongoose
Dans l’univers NoSQL, on a 2 très gros acteurs : CouchDB et MongoDB. Arbitrer entre les deux sort totalement du cadre de cet article, aussi je vais éviter, mais je suis pour ma part un énorme fan de MongoDB, et côté Node, la surcouche systématique, c’est Mongoose.
Outre qu’il propose pas mal d’APIs de haut niveau par-dessus celles déjà très riches de MongoDB, Mongoose fournit également des mécanismes avancés de schéma (valeurs par défaut, validations, relations normalisées ou dénormalisées, etc.) qui sont extrêmement utiles.
Un schéma Mongoose, et le modèle basé dessus, pourrait ressembler par exemple à ceci :
var commentSchema = mongoose.Schema({
author: { type: String, ref: 'User', required: true },
postedAt: { type: Date, default: Date.now, index: true },
text: { type: String, trim: true, required: true },
})
commentSchema.statics.getAll = function getAllComments() {
return this.find().populate('author').sort({ postedAt: -1 }).exec()
}
module.exports = mongoose.model('Comment', commentSchema)Trop mignoooonnnn…
redis
Lorsque j’ai besoin de faire du Redis (soit directement, soit indirectement, par exemple au travers de l’excellent kue pour des files de messages avancées), j’utilise le module ultra-dominant redis (quel nom original !).
Il expose l’intégralité de l’API officielle et reste bien à jour sur les évolutions. Il est 100% JavaScript (pas de partie compilée), ce qui ne pose généralement aucun souci, mais si vous vous retrouvez à dépendre de façon critique de certaines manipulations de très grosses valeurs ou de longs intervalles, vous voudrez peut-être ajouter hiredis, qui compile nativement certaines parties dédiées à ce cas de figure et peut sensiblement améliorer la perf de ce type d’accès.
Dans un serveur
Même si Node sert à énormément de choses, et notamment beaucoup à des outils en ligne de commande, c’est surtout un choix idéal pour des serveurs web, soit complets soit 100% API.
socket.io
Si j’ai besoin d’une vraie communication bidirectionnelle et temps réel entre mon serveur et mes clients, je vais passer par Socket.IO plutôt que par des alternatives plus légères et plus simples (ex. un poll Ajax toutes les 10 secondes).
Socket.IO fournit deux très gros avantages par rapport à du pur-sockets (genre socks voire ws) :
- Il fournit, côté client comme côté serveur, toute une série de protocoles de secours qui permet d’obtenir une fonctionnalité sensiblement équivalente sur des vieux navigateurs (ça marche à partir d’IE 5.5 !)
- Il ajoute au protocole binaire des Web Sockets toute une série de fonctions utiles telles que les événements, les channels (ou rooms), le heartbeat et la reconnexion, etc.
Côté serveur, c’est super simple :
var io = require('socket.io');
// …
var server = http.createServer(…);
var ws = io(server);
// Broadcast :
ws.sockets.emit('my-event', someObj, someValue…);Côté client, c’est tout aussi pipeau :
<script src="/socket.io/socket.io.js"></script>var socket = io();
socket.on('my-event', function(obj, value…) {
// Ta-daaaaam !
});J’aime.
bunyan et winston
Tout comme je vous ai cité les 3 principaux modules d’analyse des arguments de la CLI tout à l’heure, je vous donne ici les 2 poids lourds du logging avancé.
On évoquait tout à l’heure debug, qui est très bien pour balancer plus ou moins d’infos dans la console lorsqu’on débogue un projet interactivement, mais le logging n’a rien à voir : on logue même quand tout va bien, en particulier sur un serveur, pour pouvoir analyser le comportement ultérieurement.
Ces deux modules sont très, très sympa, très utilisés, très bien documentés et testés, activement développés, et offrent une pléthore de fonctions avancées, avec en particulier la possibilité de multiplexer nos logs sur toute une série de cibles (Winston parle de transports et Bunyan de flux), par exemple un syslog local, une liste Redis, une table dans un SGBD, une socket réseau, mais aussi divers services de centralisation de logs (genre Loggly, Papertrail, Logentries…).
La différence tient principalement au fait que Bunyan produit, à la base, du JSON. Il ne cherche pas forcément à faire des contenus immédiatement « consommables » par un être humain, mais en échange, il facilite le logging d’objets complexes (on a du coup tendance à loguer des grappes d’objets de manière un peu trop massive et flemmarde, avec Bunyan).
Bunyan fournit d’ailleurs, installé en global, une commande bunyan qui consomme et formate les logs JSON produits par défaut par ses loggers. Notez que malgré son format plus lisible à la base, Winston aussi fournit une API de requêtage sur les logs produits.
Les performances sont similaires, c’est donc, là aussi, avant tout une question d’esthétique de code personnelle, de philosophie/approche. Et dans une bien moindre mesure, de besoins opérationnels.
Un p’tit exemple basique avec Winston :
var winston = require('winston')
winston.add(winston.transports.File, { filename: 'logs/dev.log' })
winston.log('info', 'This goes everywhere (%d)', 42)
winston.info('Hello again distributed logs', { foo: 'bar' })Un équivalent avec Bunyan :
var bunyan = require('bunyan')
var log = bunyan.createLogger({
name: 'My App',
streams: [{ stream: process.stdout }, { path: 'logs/dev.log' }],
})
log.info('hi')
log.warn({ lang: 'fr' }, 'Salut !')Il me semble que Bunyan s’intègre mieux avec des outils de log/traçage « sysadmin », type Syslog et DTrace, ce qui peut intéresser pas mal de monde, mais je ne suis pas sûr de ce que propose Winston sur ces sujets.
passport
La plupart des serveurs ont besoin d’authentification (déterminer l’identité de l’utilisateur), que ce soit via une bonne vieille saisie login + mot de passe, ou par des tokens API en en-têtes de requête HTTP, ou par des aller-retours OAuth avec des prestataires tiers…
Le module de référence (une collection de modules, en fait) pour ça, c’est Passport.
La mise en place peut paraître un peu obscure, mais ça permet, plutôt facilement, de mettre en place toute une gamme de stratégies d’authentification pour votre service.
Voyez par exemple mon atelier Node.js démystifié à Paris Web 2014 pour des exemples de stratégies locale, Facebook et Twitter.
nodemailer
Quand mes programmes Node ont besoin d’envoyer des e-mails, je ne cherche généralement pas plus loin que l’excellent Nodemailer.
C’est une solution très complète qui gère les e-mails multi-formats, les pièces jointes, les images intégrées, les connexions STARTTLS, etc. Et qui connaît déjà toute une série de fournisseurs SMTP (notamment GMail, bien entendu) pour nous faciliter les réglages.
Petit exemple, tiré verbatim de la doc :
var nodemailer = require('nodemailer')
var transporter = nodemailer.createTransport({
service: 'Gmail',
auth: {
user: 'gmail.user@gmail.com',
pass: '…',
},
})
var mailOptions = {
from: 'Fred Foo ✔ <foo@blurdybloop.com>',
to: 'bar@blurdybloop.com, baz@blurdybloop.com',
subject: 'Hello ✔',
text: 'Hello world ✔',
html: '<b>Hello world ✔</b>',
}
transporter.sendMail(mailOptions, function (error, info) {
if (error) {
console.error(error)
} else {
console.log('Message sent:', info.response)
}
})daemon
Il m’arrive régulièrement de coder des serveurs en Node, et ceux-ci n’ont pas vocation à rester attachés à leur shell de lancement, évidemment. Ils doivent pouvoir tourner sans session attachée, ce qu’on appelle être daemonized.
Un module Node rend ça extrêmement simple : le bien-nommé daemon. L’utilisation est très concise :
require('daemon')()Sans déconner. C’est tout.
En fait le fait de faire ce require et d’appeler la fonction résultante relance le process en tant que daemon. On peut bien sûr personnaliser ça avec un hash d’options en argument, notamment pour personnaliser les redirections des flux de sorties, l’environnement et le répertoire courant.
Tests
Les tests, c’est super important. Hors des tests, point de salut (même si tester c’est douter ;-)).
mocha
De tous les harnais de tests, Mocha est sans conteste mon préféré. Il marche aussi bien côté Node (en CLI) que dans un navigateur, il offre une grande liberté dans les syntaxes de structuration de tests, les assertions, les modes de reporting (y’a même un nyancat ! Non mais sans déconner…), et se prête particulièrement bien aux tests sur du code asynchrone.
Petit exemple mixé à partir des docs, en « interface » BDD (imbrication pratique de blocs describe et it), en supposant pour le deuxième test l’utilisation de Chai as Promised pour les assertions qui renvoient des promesses, histoire de faire une combo gagnante :
describe('User', function () {
beforeEach(function () {
return db.clear().then(function () {
return db.save([tobi, loki, jane])
})
})
describe('#save()', function () {
it('should save without error', function (done) {
this.timeout(500)
var user = new User('Luna')
user.save(done)
})
it('should refuse nameless users')
})
describe('#find()', function () {
it('respond with matching records', function () {
return db.find({ type: 'User' }).should.eventually.have.length(3)
})
})
})chai et chai-as-promised
Node fournit un module noyau d’assertions, assert le bien-nommé, mais il est plutôt léger… Histoire d’avoir un vocabulaire nettement plus riche, et surtout de pouvoir utiliser la syntaxe qui me plaît (généralement should, parfois expect si je veux réutiliser les tests côté client dans IE avant la version 9), je recours à l’excellentissime Chai.
Ce dernier nous fournit un ensemble d’assertions déjà bien riche (sachant qu’une pléthore de plugins permet de s’équiper d’assertions « métier » spécifiques à notre contexte), mais aussi nous les offre suivant trois syntaxes (Chai parle de styles) possibles :
- Les bons vieux
assert - Le style
expectqu’on retrouve par exemple avec Jasmine - Le style
should, qui n’est toutefois possible que dans un context ES5+ (donc Node, IE9+ et les autres navigateurs). C’est celui que je préfère.
Voici une petite comparaison issue de la doc.
Le style assert :
var assert = require('chai').assert,
foo = 'bar',
beverages = { tea: ['chai', 'matcha', 'oolong'] }
assert.typeOf(foo, 'string', 'foo is a string')
assert.equal(foo, 'bar', 'foo equal `bar`')
assert.lengthOf(foo, 3, 'foo`s value has a length of 3')
assert.lengthOf(beverages.tea, 3, 'beverages has 3 types of tea')Le style expect :
var expect = require('chai').expect,
foo = 'bar',
beverages = { tea: ['chai', 'matcha', 'oolong'] }
expect(foo).to.be.a('string')
expect(foo).to.equal('bar')
expect(foo).to.have.length(3)
expect(beverages).to.have.property('tea').with.length(3)Le style should :
var should = require('chai').should(), //actually call the the function
foo = 'bar',
beverages = { tea: ['chai', 'matcha', 'oolong'] }
foo.should.be.a('string')
foo.should.equal('bar')
foo.should.have.length(3)
beverages.should.have.property('tea').with.length(3)Re-trop mignooonnnn…
C’est déjà le top en soi, mais ça pourrait être encore mieux quand on fait de l’asynchrone. Les tests asynchrones dans Mocha sont déjà très simples à gérer : il suffit de déclarer un paramètre dans notre fonction de test, lequel est alors automatiquement rempli par un callback de continuation, à appeler une fois tous nos tests effectués. Par exemple :
describe('User', function () {
it('should save properly', function (done) {
user.save().then(
function (result) {
result.should.not.be.null
done()
},
function (err) {
done(err)
}
)
})
})C’est pas mal, mais en fait, Mocha va aussi attendre la fin de votre test asynchrone si celui-ci renvoie une promesse. Il n’est alors pas nécessaire de déclarer un paramètre pour le callback de continuation.
En revanche, il faut alors faire en sorte que l’assertion voulue renvoie une promesse. C’est précisément ce que permet Chai as Promised, qui équipe les assertions d’un modificateur eventually (qui, je vous le rappelle, signifie en anglais « finalement », « à terme », et non pas « éventuellement »). On pourrait donc réécrire le code précédent comme ceci :
describe('User', function () {
it('should save properly', function () {
return user.save().should.eventually.not.be.null
})
})La classe à Dallas !
sinon
Dans les tests unitaires, il est indispensable de bien isoler le code testé de son environnement, pour diverses raisons :
- Certaines dépendances ne sont pas encore écrites,
- Elles sont écrites mais peuvent avoir des bugs,
- Elles n’ont pas de problèmes mais on veut en simuler pour vérifier notre gestion dans ces cas-là,
- Elles sont lentes et on veut des tests super rapides,
- etc.
On aura donc recours au stubs et aux mocks pour isoler tout ça et simuler des environnements appropriés à nos tests, et aussi rapides que possibles.
Dans l’univers JavaScript, que ce soit serveur ou client, la référence absolue pour tout ça c’est Sinon.JS. Une vraie merveille qui nous permet de stubber des méthodes (pour en contrôler les retours, par exemple), de prendre la main sur le temps (pour accélérer des tests de traitements longs ou périodiques) et même de simuler le serveur !
Si par exemple vous avez du code qui prompte l’utilisateur, vous ne voulez pas de ça dans un test automatisé, qui ne doit pas nécessiter d’interactions manuelles… On pourrait faire :
var prompt = sinon.stub(window, 'prompt').returns('Roberto')
// Le corps de test ici…
prompt.restore()Peut-être êtes-vous en train de tester qu’un poll Ajax a bien lieu toutes les 15 secondes ? Mais hors de question que votre test attende 15 secondes à chaque fois. Prenons la main sur le temps :
var clock = sinon.useFakeTimers()
// Test initial, puis…
clock.tick(15 * 1000)
// Test en situation « 15 seconds plus tard »
clock.restore()Et que dire de la simulation du serveur pour notre code client ? Il n’est pas toujours possible d’avoir le serveur opérationnel pour les tests, et même si c’était le cas, les APIs qu’on souhaite appeler ne sont pas forcément disponibles, ou marchent mal, ou marchent alors qu’on veut tester quand ça ne marche pas, ou sont simplement lentes ou complexes à initialiser…
Mais on peut isoler nos tests du serveur, ce qui est juste le top, du moment qu’on a les specs de l’API à appeler !
var server = sinon.fakeServer.create()
// Début du test, qui fait en interne des appels Ajax, par exemple
// ici un POST de création d'entité. On veut tester qu'on
// fusionne bien l'id retourné par le corps de la réponse 201.
var checkIn = new CheckIn({ place: 'L’Amphitryon' })
checkIn.save()
// On simule le serveur !
server.requests[0].respond(
201, // Le code
{ 'Content-Type': 'application/json' }, // Les en-têtes
'{"id":42}' // Le corps
)
// Et on vérifie le résultat côté client.
checkIn.isNew().should.be.false
checkIn.id.should.equal(42)
server.restore()On tombe vite amoureux de Sinon…
blanket
J’aime bien avoir une vision claire de la couverture de tests de mon code. En combinant avec un outil de type Coveralls, je peux suivre ça au fil du temps et me faire taper sur les doigts si la couverture est trop faible…
On trouve plusieurs modules dominants dans l’univers Node, les deux principaux étant Blanket et Istanbul.
Le second est plus fin/malin que le premier, mais je n’ai pas encore réussi à le rendre aussi transparent que Blanket : avec ce dernier, le simple fait de le requérir avant mes tests instrumente mon code à la volée, alors qu’avec Istanbul, il faut apparemment produire une version instrumentée de la codebase, si j’en crois tous les tutos et la doc… Je ne suis pas très fan, ça me rappelle trop node-coverage.
Pour utiliser Blanket, il suffit de :
- Dire à Mocha de charger
blanketd’abord pour prendre la main sur lesrequire; on utilisera l’option de ligne de commande-rpour ça. - Utiliser un reporter Mocha dédié à la couverture de tests, par exemple
html-cov, grâce à l’option-R. - Configurer Blanket pour lui dire quoi instrumenter, grâce à la partie
configdupackage.json.
On ajouterait donc à notre package.json un bloc de ce genre :
"config": {
"blanket": {
"pattern": "app",
"data-cover-never": "node_modules"
}
},Et l’invocation ressemblerait à ceci :
$ mocha -r blanket -R html-cov > test/coverage.html
Voyez un exemple de résultat avec la couverture de tests d’Express (c’est pas la dernière version, mais ça donne une idée…).
Envie d’en savoir plus ?
On a une formation Node magnifique, qui fait briller les yeux et frétiller les claviers : pour découvrir, apprivoiser puis maîtriser le nouveau chouchou de la couche serveur, qui envoie du gros pâté !