Anatomie d’un commit Git
Par Maxime Bréhin • Publié le 25 janvier 2022
• 9 min
Et si on prenait l’élément constituant de base Git, le commit, et qu’on le décortiquait pour découvrir son anatomie ? Je vous propose dans cet article d’autopsier un commit pour comprendre tout un tas d’autres mécanismes qui en découlent ! À vos scalpels !
Avant cet article vous voudrez peut-être explorer le fonctionnement des zones ou encore apprendre à maîtriser la commande add.
Vous préférez une vidéo ?
Si vous êtes du genre à préférer regarder que lire pour apprendre, on a pensé à vous :
Rôle d’un commit
Avant d’attaquer la découpe, il me semble nécessaire de faire un pas de côté et d’analyser les intentions que servent un commit.
Un commit est une unité de travail participant à un projet, une brique de l’édifice projet. On parle souvent de commit « atomique » pour une unité de travail cohérente, représentant « un tout ». C’est l’usage recommandé, même s’il ne peut être contraint. La meilleure représentation qu’on puisse s’en faire est la réalisation pleine d’une tâche décrite par la gestion de projet (cette tâche étant la plus petite possible).
Le commit a la charge d’enregistrer les modifications* sur les fichiers et répertoires ainsi que les informations utiles à un suivi, ce qu’on appelle les métadonnées :
- L’identité de l’auteur : nom, e-mail ;
- Le message renseigné par l’auteur, censé décrire le contenu des modifications apportées ;
- La date de création du commit par l’auteur ;
- L’identité du commiteur : nom, e-mail (généralement identiques à l’auteur) ;
- La date de réalisation du commit par le commiteur ;
- Les éventuelles références des commits parents ;
- Une signature GPG, optionnelle.
On distingue les rôles d’auteur et commiteur pour assurer un suivi efficace dans des cas comme :
- le réemploi d’un commit d’un endroit à un autre (patch, cherry-pick) ;
- la modification d’un commit (amend, rebase) ;
- la réalisation d’une commit en pair-programming.
On garantit ainsi cette distinction entre la personne qui a réalisé la tâche et celle qui a créé le commit.
*Techniquement Git ne stocke pas les modifications mais des instantanés complets des fichiers.
Note : si vous utilisez les notes Git (c’est-à-dire git notes), leurs informations ne sont pas stockées dans le commit, mais dans un objet commitish dédié faisant référence au commit.
En résumé, le rôle du commit est d’enregistrer un lot de travail, d’indiquer qui l’a réalisé, à quel moment et à partir de quel état du projet.
Unchain my heart commits 🎶
Poussons un peu plus loin que le simple commit et parlons des commits et des liens qu’ils entretiennent. Lorsqu’on construit un historique Git, on crée une série de commits qui se référencent par lien de parentalité. Vous voyez ces schémas qui nous montrent des flèches qu’on peut croire dans le « mauvais » sens ?

En réalité, chaque flèche exprime la référence parente détenue par le commit dont elle part. C’est un point absolument fondamental à la bonne compréhension de certaines mécaniques de Git : un historique Git est exprimé par le chaînage des commits entre eux. Si on creuse encore plus loin, on s’aperçoit même que tout le fonctionnement de Git est basé sur des références d’objets Git entre eux (branches, HEAD, commitishs, blobs, trees, etc). Mais ça sort du périmètre de cet article.
Autopsie
Ça, c’était en surface. Sortons maintenant le scalpel et découvrons la manière dont est composé mon commit, et pourquoi ?
Je pars de l’exemple d’un projet initialisé avec les répertoires src et log et les fichiers .gitignore et README.md.
.
├── .gitignore
├── README.md
├── log
│ └── .keep
└── src
└── .keepLe commit initial est déjà réalisé via la commande git commit -m 'Initial commit' et possède l’identifiant b4cf8aec80f87ac6a1e21e47ffc42dd4ec53ef2a.
Pour analyser un objet de type commit (ou commitish) je peux utiliser la commande show en lui passant la référence de l’objet (ou toute autre référence dont la résolution revient au même) :
> git show b4cf8aec80f87ac6a1e21e47ffc42dd4ec53ef2a
commit b4cf8ae
Author: Maxime Bréhin <maxime@delicious-insights.com>
Date: Thu Jan 20 15:28:17 2022 +0100
Initial commit
─────────────────────────────────────────────────────────
added: .gitignore
─────────────────────────────────────────────────────────
@ .gitignore:1 @
tmp/*
log/*
*.tmp
*.swap
\ No newline at end of file
─────────────────────────────────────────────────────────
added: README.md
─────────────────────────────────────────────────────────
@ README.md:1 @
This is a demo projet.
─────────────────────────────────────────────────────────
added: log/.keep
─────────────────────────────────────────────────────────
─────────────────────────────────────────────────────────
added: src/.keep
─────────────────────────────────────────────────────────Note : mon affichage est enrichi dans le terminal par l’utilitaire diff-so-fancy.
J’obtiens les informations générales constituant mon commit : les métadonnées principales (auteur, date, message) et les modifications :
- ajout du fichier
.gitignoreet détail de son contenu ; - ajout du fichier
README.mdet détail de son contenu ; - ajout du fichier vide
log/.keep(pour enregistrer la présence du répertoirelog) ; - ajout du fichier vide
src/.keep(pour enregistrer la présence du répertoiresrc).
Je ne vais cependant pas m’arrêter là, car la commande show ne fournit pas les détails que je souhaite vous montrer. L’ensemble des objets techniques Git qui nous intéressent sont stockés dans le répertoire .git/objects/. Mais je me casserais le nez à essayer d’y accéder directement car ils font l’objet d’optimisations sur le disque et sont illisibles tels quels. Je vais donc utiliser la commande de plomberie* cat-file pour afficher le contenu-même des objets techniques associés qui m’intéressent, à commencer par mon commit.
* Git offre environ 110 commandes réparties en 2 grandes catégories : la porcelaine (≈ 40) et la plomberie (le reste). Presque tout le monde se contente d’utiliser la porcelaine, la plomberie étant généralement réservée a du script ou des besoins très spécifiques.
> git cat-file -p b4cf8aec80f87ac6a1e21e47ffc42dd4ec53ef2a
tree 6df8433ebd2517c43aff68ff14e726cd788ad84d
author Maxime Bréhin <maxime@delicious-insights.com> 1642688897 +0100
committer Maxime Bréhin <maxime@delicious-insights.com> 1642688897 +0100
Initial commitDécryptons ce nouvel affichage :
- la première ligne renseigne une référence vers un objet de type tree ;
- les autres lignes renseignent le reste des métadonnées : auteur, commiteur, message.
Cet objet tree est la représentation du niveau de répertoire racine de notre projet, mais ça se saute pas aux yeux ici. Je vais donc creuser pour savoir ce qu’il contient en passant sa référence à la commande cat-file :
> git cat-file -p 6df8433ebd2517c43aff68ff14e726cd788ad84d
100644 blob 1cb865f27fa00fa0cd3d5ef0a3df729ea636413a .gitignore
100644 blob 7398b8548a6bd59ae49a524388e23d699b3edc23 README.md
040000 tree 29a422c19251aeaeb907175e9b3219a9bed6c616 log
040000 tree 29a422c19251aeaeb907175e9b3219a9bed6c616 srcCette fois j’obtiens un tableau de références dont la structure est la suivante :
- droits / mode (essentiellement fichier classique, exécutable, répertoire) ;
- type de fichier Git ;
- identifiant ;
- nom associé.
On comprend ici que Git représente fidèlement les répertoires et fichiers à travers ses objets :
- Un fichier est représenté par un blob (Binary Large Object) ;
- un répertoire par un tree ;
- un tree contient des références vers des trees et blobs.
Dans l’exemple courant, notre objet tree contient la liste des autres objets Git qui modélisent le répertoire racine du projet au moment du commit, à savoir :
- un fichier
.gitignoredont le contenu est celui du blob de référence1cb865f27fa00fa0cd3d5ef0a3df729ea636413a; - un fichier
README.mddont le contenu est celui du blob de référence7398b8548a6bd59ae49a524388e23d699b3edc23; - un répertoire
logdont le contenu est celui du tree de référence29a422c19251aeaeb907175e9b3219a9bed6c616; - un répertoire
srcdont le contenu est celui du tree de référence29a422c19251aeaeb907175e9b3219a9bed6c616;
Attends, attends : qu’est-ce que c’est que ce truc ? log et src ont le même idenfitiant technique, c’est impossible !
Ahah, on pourrait croire à une erreur en effet, mais c’est tout à fait normal du point de vue Git. Je vous explique tout ça un peu plus bas, histoire d’avoir toutes les cartes en main (et de laisser un peu de suspense 😉). En tout cas, pas de panique, vous ne ratez rien d’essentiel si vous ne comprenez pas ce point.
Revenons à notre liste et voyons à quoi ressemble le contenu de notre premier blob :
> git cat-file -p 1cb865f27fa00fa0cd3d5ef0a3df729ea636413a
tmp/*
log/*
*.tmpLe blob contient l’instantané du fichier, c’est-à-dire l’intégralité du contenu du fichier .gitignore du projet au moment où le commit à été réalisé.
Voyons enfin les objets réprésentant nos sous-répertoires log et src, dont on a vu plus haut qu’ils possédaient la même référence :
> git cat-file -p 29a422c19251aeaeb907175e9b3219a9bed6c616
100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 .keepJe retrouve le même type affichage que mon objet tree vu précédemment. Celui-ci décrit la présence dans src (et log) d’un unique fichier .keep représenté par le blob d’identifiant e69de29bb2d1d6434b8b29ae775ad8c2e48c5391.

Ça, c’était le découpage du commit « de haut en bas ». Maintenant rembobinons ⏪ et voyons les étapes qui amènent à l’obtention d’un commit et la constitution des objets au fil de l’eau.
Mais avant ça…
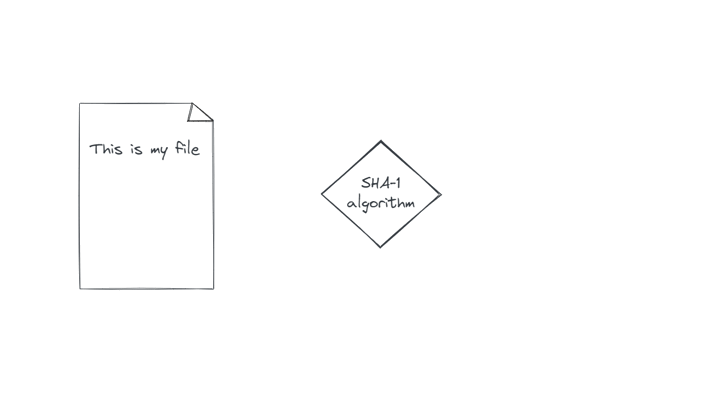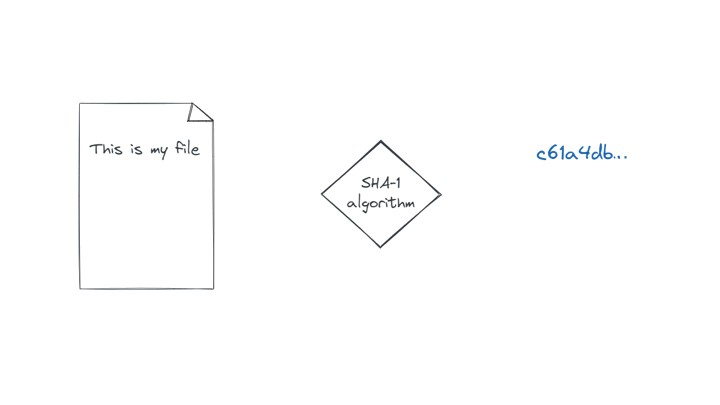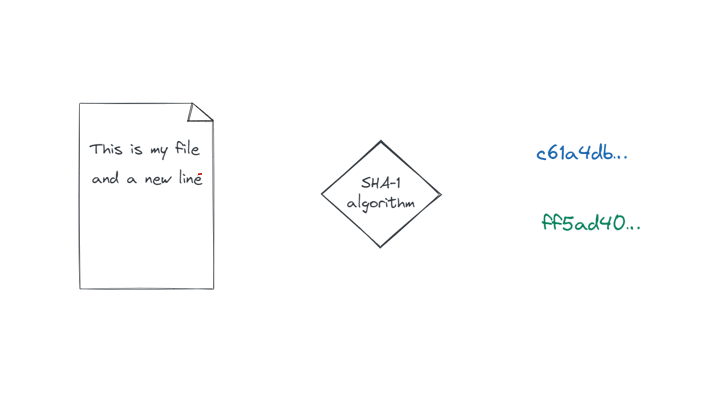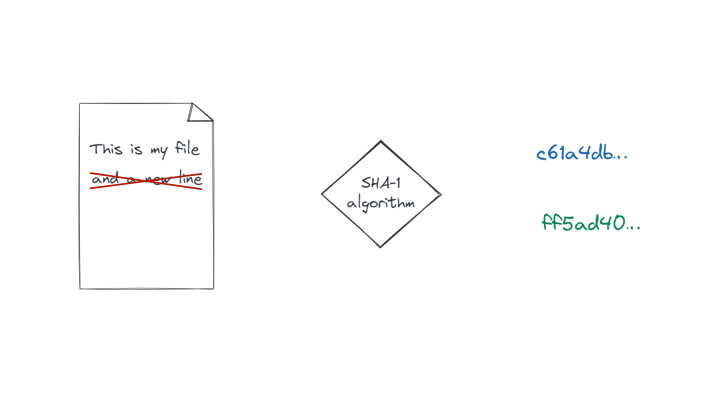
J’aimerais revenir sur cet histoire d’identifiants des objets Git. Vous avez vu, ils ont tous la même tête ! 40 caractères hexadécimaux. Bon en vrai on peut utiliser ces identifiants dès 5 caractères, et en cas d’ambiguïté Git nous le dirait. Passons. Ce qui m’intéresse particulièrement ici, c’est la manière dont ils sont créés, ou plus exactement ce qui sert à les définir. Un idenfitiant est produit en se basant sur le contenu (binaire) de l’objet qu’il représente, ou si vous préférez depuis le résultat obtenu ci-avant par l’emploi de la commande cat-file. Pour l’aspect technique, ce contenu est passé à un algorithme de hachage appelé SHA-1* (prononcez « chawouane » 🍵) qui produit cette représentation sur 20 octets, soit 40 caractères hexadécimaux.
Pour un blob, le contenu est l’instantané (copié/collé) du corps du fichier qu’il représente. Donc nos fichiers log/.keep et src/.keep n’ont qu’un blob unique pour les représenter (ce qui représente au passage une optimisation d’espace disque de la part de Git). Il en va de même pour les trees représentant log/ et src/. Voilà, notre mystère est élucidé 🔍 !
Du fait des références en cascade, toute modification d’un fichier implique la création d’un nouveau blob, d’un nouveau tree représentant le répertoire qui le contient, et ainsi de suite en remontant jusqu’au répertoire racine du projet (on remonte la cascade). À l’inverse, tout retour à un contenu correspondant à une version antérieure d’un fichier réutilisera la référence Git de l’objet blob correspondant.
* SHA-256 est en expérimentation depuis Git 2.29.
Construction d’un commit
Je vais créer un nouveau commit depuis l’état actuel du projet qui modifie le fichier README.md et ajoute un nouveau fichier src/index.js :
.
├── .gitignore
├── README.md # contenu modifié
├── log
│ └── .keep
│ └── index.js # nouveau fichier
└── src
└── .keepJe vous décris au fil de mes actions ce qui se passe dans le sous-répertoire .git/objects en commençant par son état actuel :
# J’ai annoté chaque objet pour que vous vous y
# retrouviez plus facilement.
.git/objects/
├── 1c # Blob du fichier `.gitignore`
│ └── b865f27fa00fa0cd3d5ef0a3df729ea636413a
├── 29 # Tree pour `log` et `src`
│ └── a422c19251aeaeb907175e9b3219a9bed6c616
├── 6d # Tree de niveau racine lié au commit initial
│ └── f8433ebd2517c43aff68ff14e726cd788ad84d
├── 73 # Blob du fichier `README.md`
│ └── 98b8548a6bd59ae49a524388e23d699b3edc23
├── b4 # Mon premier commit (initial)
│ └── cf8aec80f87ac6a1e21e47ffc42dd4ec53ef2a
├── e6 # Blob des fichiers vides `log/.keep` et `src/.keep`
│ └── 9de29bb2d1d6434b8b29ae775ad8c2e48c5391On retrouve nos références vues précédemment, mais dans des répertoires, découpés par les 2 premiers caractères des références qui y figurent. Pour la petite histoire, ce découpage est un contournement à la contrainte de nombre maximal d’objets fils imposées par certains systèmes de fichiers (FAT32 limite à 65 534 fichiers par répertoire, par exemple).
1. Ajout au stage avant le commit
J’attaque avec l’ajout de toutes les modifications via un git add --all. Mon répertoire .git/objects a reçu deux nouveaux fichiers. Je vous épargne l’analyse des contenus et note juste leurs correspondances :
.git/objects/
├── 18 # Blob pour `src/index.js`
│ └── 7371973809001933ec3d4be71a0e6acd24dbbc
├── 1c
│ └── b865f27fa00fa0cd3d5ef0a3df729ea636413a
├── 29
│ └── a422c19251aeaeb907175e9b3219a9bed6c616
├── 6d
│ └── f8433ebd2517c43aff68ff14e726cd788ad84d
├── 73 # Version du `README.md` liée au commit initial
│ └── 98b8548a6bd59ae49a524388e23d699b3edc23
├── b4
│ └── cf8aec80f87ac6a1e21e47ffc42dd4ec53ef2a
├── e3 # Blob pour `README.md` à jour
│ └── ab945e72a3d64dd76248f1933c0fd70fa68c74
├── e6
│ └── 9de29bb2d1d6434b8b29ae775ad8c2e48c5391On constate que dès l’ajout au stage, Git enregistre les instantanés des nouvelles modifications, mais seulement les blobs. On note aussi que les fichiers précédents ne sont pas touchés. Une nouvelle version de README.md n’écrase pas sa version précédente, celle-ci étant liée au commit précédent. Suivant cette même logique, si je produisais une nouvelle modification sur le fichier README.md et que je l’ajoutais à nouveau avec un git add …, j’obtiendrais un nouveau blob.
À cette étape, ni tree, ni commit, mais un fichier intermédiaire qui représente le stage et stocke les références de ces blobs : .git/index. On peut obtenir une idée de ce que contiendrait le prochain commit et tree en utilisant la commande de plomberie git ls-files --stage :
100644 1cb865f27fa00fa0cd3d5ef0a3df729ea636413a 0 .gitignore
100644 e3ab945e72a3d64dd76248f1933c0fd70fa68c74 0 README.md
100644 e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 0 log/.keep
100644 e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 0 src/.keep
100644 187371973809001933ec3d4be71a0e6acd24dbbc 0 src/index.js2. Validation et création du commit
Mon stage est prêt, je valide avec git commit -m 'Second commit' (j’ai fait original pour le message 😁). On observe, en plus de nos 2 nouveaux blobs, 3 autres références :
- une pour le commit ;
- une pour l’objet tree de niveau racine ;
- une pour l’objet tree
srcqui référence en plus du.keep, le fichierindex.js.
.git/objects/
├── 18 # Blob pour `src/index.js`
│ └── 7371973809001933ec3d4be71a0e6acd24dbbc
├── 1c
│ └── b865f27fa00fa0cd3d5ef0a3df729ea636413a
├── 29
│ └── a422c19251aeaeb907175e9b3219a9bed6c616
├── 4c # Tree représentant la version à jour de `src/`
│ └── 2f911ae9ac7ef74e80fb986607934b708320ad
├── 6d
│ └── f8433ebd2517c43aff68ff14e726cd788ad84d
├── 73 # Version du `README.md` liée au commit initial
│ └── 98b8548a6bd59ae49a524388e23d699b3edc23
├── b4
│ └── cf8aec80f87ac6a1e21e47ffc42dd4ec53ef2a
├── d9 # Mon nouveau commit
│ └── ed106dc9431807ad144e814dad4890b507e5af
├── e3 # Blob pour `README.md` à jour
│ └── ab945e72a3d64dd76248f1933c0fd70fa68c74
├── e6
│ └── 9de29bb2d1d6434b8b29ae775ad8c2e48c5391
├── f4 # Tree de niveau racine
│ └── 5c454fbcc18d35def1125924dd4bb5164e8a88Les contenus des nouveaux fichiers blobs et trees sont sans surprise, mais laissez-moi vous montrer le nouveau commit :
> git cat-file -p d9ed106dc9431807ad144e814dad4890b507e5af
tree f45c454fbcc18d35def1125924dd4bb5164e8a88
parent b4cf8aec80f87ac6a1e21e47ffc42dd4ec53ef2a
author Maxime Bréhin <maxime@delicious-insights.com> 1642690996 +0100
committer Maxime Bréhin <maxime@delicious-insights.com> 1642690996 +0100
Second commitVous voyez cette deuxième ligne qu’on n’avait pas dans notre premier commit ?
parent b4cf8aec80f87ac6a1e21e47ffc42dd4ec53ef2a
Elle renseigne la référence du commit parent (ou des commits parents dans le cas d’un commit de fusion). Cette référence b4cf8aec80f87ac6a1e21e47ffc42dd4ec53ef2a est celle de notre précédent commit. C’est ce qui chaîne nos commits. En réalité l’exception était celle du commit précédent, car seul* le commit initial apparaîtra sans parent dans notre historique.
*Il existe des cas particuliers où on aurait plusieurs commits de ce type, mais je ne vous en parlerai pas ici 😉.
Revoyons l’action au ralenti
- L’ajout au stage avec
git addcrée les blobs correspondants aux fichiers modifiés :- leurs identifiants (SHA-1) sont générés depuis leur contenu ;
- les blobs sont stockés dans le répertoire
.git/objects; - leur référence est inscrite dans le fichier
.git/index.
- La validation du stage crée le commit et les objets trees représentant les répertoires qui contiennent des modifications :
- les éléments sont lus depuis le stage (techniquement
git/index) ; - les nouveaux trees pour représenter les répertoires sont créés, y compris le niveau racine ;
- les autres trees et blobs inchangés sont référencés en l’état par ces nouveaux trees* ;
- le commit est écrit avec ses métadonnées, la référence du tree de niveau racine, et les références des commits parents.
- les éléments sont lus depuis le stage (techniquement
*Le commit représente ainsi l’intégralité de l’état du projet à un instant T. Sa lecture suffit à récupérer cet état, nul besoin de traverser d’autres commits pour avoir l’information.
Ce qu’il faut retenir
C’est vrai que tout ça est assez technique, mais plusieurs points sont à retenir :
- un commit enregistre non pas des différences, mais bien un état de notre projet ;
- les métadonnées d’un commit permettent un suivi efficace du projet (pensez à bien renseigner vos messages, hein 😉 !) ;
- l’historique d’un projet est constitué de la succession des références des commits entre eux ;
- un commit, comme tout objet Git, est associé à un identifiant unique (le SHA-1) ;
Une partie de la magie noire 🧙♂️ de Git vous a été révélée, vous avez désormais un grand pouvoir, celui de comprendre ce que vous faites avec Git.