Pourquoi je préfère Brunch
Par Christophe Porteneuve • Publié le 4 mars 2015
• 41 min
Ah, vous croyez que vous êtes au top parce que vous utilisez Grunt, Gulp, Broccoli ou même Glou ? Eh ben non, pas forcément, voire carrément pas. Du tout. Voilà déjà 4 ans que Brunch existe, et sur bien des scenarii courants, il bat tout ce petit monde à plate couture.
Envie d’en savoir plus, et de voir plein d’exemples ? C’est par ici.
UPDATE: This article has been translated to English and adapted to become the official Brunch Guide (EN/FR). Only the Guide will be maintained and updated looking forward.
Brunch ?! C’est quoi, Brunch ?
Brunch est un builder. Pas un exécuteur de tâches générique, mais un outil spécialisé dans la production de fichiers finaux pour la production, à partir de tout un tas de fichiers de développement.
Ce type de besoin est extrêmement fréquent chez les devs front et les designers front, qui ont souvent besoin de faire un peu les mêmes choses : partir d’une arborescence de fichiers LESS ou SASS pour produire un ou plusieurs CSS minifiés, pareil pour du JS, des images et leurs sprites, etc.
Brunch face aux autres
L’immense majorité des personnes qui automatisent ce type de tâches utilisent soit Grunt, soit Gulp (et parfois Broccoli ou Glou). Bien qu’extrêmement populaires, et arrivés sur le marché plus récemment que Brunch, ces solutions lui sont souvent inférieures dans les scenarii d’utilisation courants.
J’utilise Brunch depuis juin 2012 (autour de sa version 1.3 ; il remonte au printemps 2011), et jusqu’à présent, il constitue encore pour moi une alternative très supérieure aux autres acteurs apparus depuis.
Afin de bien cerner ce qui distingue Brunch des autres solutions du marché, nous allons aborder différents aspects techniques et architecturaux, qui constituent chacun des choix de conception autour desquels se répartit l’écosystème.
Après quoi, on se tapera tout plein de démos sur du code concret, n’ayez crainte.
Exécuteurs de tâches vs. outils de build
Le marché est dominé par des exécuteurs de tâches génériques. Ces outils fournissent un mécanisme de description de tâches, et de dépendances entre ces tâches. Il peut s’agir de n’importe quoi : copier un fichier, en produire un, envoyer un e-mail, compiler quelque chose, lancer les tests, faire un commit Git… absolument ce que vous voulez.
C’est une notion très ancienne ; un des premiers exécuteurs de tâche génériques connus était Make (et ses fameux fichiers Makefile) ; dans l’univers Java, on a d’abord eu Ant, et comme si ça n’était pas assez verbeux, on a désormais l’énorme mammouth sclérosé qu’est Maven ; Ruby de son côté a Rake, etc.
Parce que ces exécuteurs sont génériques, il ne leur est que rarement possible d’optimiser automatiquement pour des scenarii spécifiques, ou même de mettre en place des conventions par défaut. Toute tâche nécessite l’écriture d’un volume non trivial de code et/ou de configuration, et doit être invoquée explicitement aux bons endroits.
Qui plus est, toute tâche—et même tout comportement de fond, comme la surveillance des fichiers pour mettre à jour le build—nécessite l’écriture d’un plugin, son chargement, sa configuration, etc.
Brunch est un outil de build.
Brunch est fondamentalement spécialisé dans le build d’assets, ces fichiers qui seront utilisés à terme par la plate-forme d’exécution, en général le navigateur. Il fournit donc d’entrée de jeu un certain nombre de comportements et fonctionnalités. On y trouve notamment :
- la catégorisation des fichiers sources : JavaScript, Feuilles de style, Templates ou « divers » ;
- la concaténation intelligente de ces fichiers vers un ou plusieurs fichiers cibles ;
- l’enrobage en modules des fichiers catégorisés JavaScript ;
- la production des source maps associées ;
- la minification des fichiers produits si on est en « mode production » ;
- la surveillance des fichiers sources pour mettre à jour le build à la volée.
Toutes ces fonctionnalités sont rendues possibles grâce à la spécialisation de l’outil, mais restent très simples d’emploi (le plus souvent, carrément automatiques) grâce à un jeu habile de conventions, que nous verrons tout à l’heure.
Traitements de fichiers vs. pipelines
La faiblesse principale de Grunt est la même que pour Make, Ant et Maven, qui l’ont inspiré : il repose entièrement sur la notion de fichiers. Toute tâche qui manipule du contenu part d’un fichier pour aboutir à un autre.
Cette approche est extrêmement limitative dès qu’on touche à des workflows fréquents, où la modification d’un unique fichier source peut impacter plusieurs destinations, par exemple une concaténation, la source map associée, un manifeste AppCache… Dans Grunt, on passe son temps à produire des fichiers temporaires pour les étapes intermédiaires de traitement, ce qui est un foutoir sans nom.
L’autre inconvénient majeur de cette approche, c’est qu’elle est désastreuse en performances : on passe sa vie à fermer et rouvrir les mêmes fichiers, à les relire autant de fois que nécessaire, même pour une seule passe de build.
L’alternative, c’est la pipeline : on connecte les fichiers entre eux au travers de diverses déclarations de dépendances, et lorsqu’un fichier change, son nouveau contenu n’est lu qu’une fois, pour pouvoir être traité par toute une série d’étapes consommatrices, successives ou parallèles.
C’est l’approche fondamentale de Gulp, également retenue par Broccoli, Glou, et naturellement Brunch.
Brunch est une pipeline.
Mais toutes les pipelines ne sont pas égales, et leurs performances peuvent différer considérablement. Ainsi, Gulp reste beaucoup trop lent pour une utilisation « watcher » confortable, alors que Brunch et Glou, notamment, peuvent être extrêmement rapides.
Configuration et boilerplate vs. conventions
Dans la plupart des catégories d’outils informatiques, on va trouver deux approches : celle basée sur le code et la configuration d’une part, et celle basée sur les conventions d’autre part.
La première a le mérite d’être explicite, dénuée de toute « magie » pour un débutant, mais au prix d’une verbosité souvent rebutante et contre-productive, avec énormément de boilerplate : les mêmes segments de code copiés-collés d’un projet à l’autre jusqu’à plus soif, qui noient le sens de la tâche sous des tartines de code à faible valeur ajoutée.
La seconde minimise le code ou la configuration nécessaire à ce qui change du « chemin habituel », lequel est inscrit dans les conventions retenues par l’outil. Suivez les conventions, et vous n’aurez rien (ou presque) à écrire ou personnaliser ; sortez-en, et là vous devrez écrire du code ou configurer l’outil pour vos besoins propres. L’avantage : la concision et l’expressivité de votre contenu, qui ne dit rien de superflu. L’inconvénient : pour quiconque n’a pas lu la doc (et les développeurs détestent lire la doc, pensant tous avoir la science infuse…), ça donne le sentiment d’être un peu trop « magique ».
Brunch repose sur des conventions solides, réduisant la configuration au minimum vital.
Ce choix architectural est bien connu sous le nom de Convention Over Configuration, ou COC, et c’est par exemple celui de Ruby on Rails ou d’Ember.js. C’est aussi celui de Brunch.
Builds intégraux vs. builds incrémentaux
La majorité des exécuteurs de tâches et outils de builds proposent deux modes : le build unique (one-shot) ou le watcher. Dans ce deuxième mode, l’outil réalise le premier build, puis surveille les fichiers et répertoires pertinents pour détecter toute modification ultérieure ; il déclenche alors immédiatement une mise à jour du build.
Cette mise à jour peut elle aussi avoir deux approches distinctes : soit elle reconstruit tout à partir du début (ce qui ne nécessite aucune connaissance particulière de la sémantique des tâches concernées), soit elle ne relance que les étapes de construction nécessaires au vu des modifications constatées, pour minimiser le travail de mise à jour.
Cette deuxième voie est évidemment préférable en termes de performances, et peut faire la différence entre un build de 2 secondes et un autre de 0,2 secondes, voire entre un de 50s et un de 0,5s. Mais pour y parvenir, il faut une description fine des dépendances entre les tâches, généralement au moyen d’une pipeline, ainsi qu’un mécanisme de mise en cache des produits intermédiaires. On parle alors de build incrémental.
Je n’ai que récemment découvert, abasourdi, que Grunt et Gulp n’opéraient pas selon cette approche ; des plugins existent apparemment pour Gulp, mais leur configuration appropriée est semble-t-il souvent complexe, pour des résultats sous-optimaux.
Brunch fait du build incrémental.
Pour ma part, cette approche est la seule qui vaille le coup ; sans elle, les performances du watcher sont minables, trop lentes pour être réellement utiles tout au long de la journée. C’est à tel point une évidence pour moi qu’il ne m’était même pas venu à l’idée que Grunt et Gulp procédaient différemment.
Brunch opère évidemment ainsi depuis toujours, et Glou aussi, d’ailleurs.
L’importance primordiale de la vitesse
Vous avez remarqué que dans les points précédents, la vitesse revenait toujours comme préoccupation centrale. Il y a une bonne raison à cela.
Pour être vraiment utiles, pour nous procurer réellement le confort de travailler sur un nombre quelconque de fichiers sources de tous types (JS, CoffeeScript, TypeScript, ES6 voire ES7, React, LESS, SASS, Stylus, Handlebars, Jade, Dust, et que sais-je encore…) tout en conservant la possibilité de voir nos modifications dans le navigateur des centaines de fois par jour, il faut que le watcher de l’outil soit à même de mettre à jour le build vite.
Vite, ça veut dire en-dessous de 300ms, même pour des cas lourds et complexes. Pour des cas simples, ça devrait être l’affaire de 20 à 50ms, tout au plus.
Cela peut vous sembler excessif, mais dès qu’on dépasse ça pour atteindre 2, 3 voire 10 secondes, comme c’est trop fréquemment le cas avec Grunt ou Gulp, qu’obtient-on ? Des développeurs et designers qui passent plus de temps à regarder la console de leur outil après chaque sauvegarde de fichier qu’à regarder le résultat de leur modification dans le navigateur.
Les merveilles de l’injection à la volée du CSS ou du JS dans la page ouverte ne servent à rien si on doit commencer par attendre plusieurs secondes que le build soit mis à jour. Même un bon vieux Alt+Tab suivi d’un rafraîchissement se prend les pieds dans le tapis s’il doit d’abord attendre plusieurs secondes. La boucle de feedback s’effondre, sa courroie grippe trop.
Brunch est ultra-rapide.
Si vous voulez voir à quoi ressemble un feedback efficace, regardez donc cet extrait de mon screencast « Dev Avengers pour le web front », vous allez voir. Il me suffit d’observer les yeux de l’auditoire quand je montre ça pour bien sentir à quel point les fronteux ont faim de ça.
Mais alors pourquoi entend-on seulement parler des autres ?
En un mot ? Le marketing.
Grunt a été le premier à faire vraiment parler de lui (à partir du 2e semestre 2012), et son développement a continué avec sa sélection comme outil de build par l’écosystème Angular ; il a connu un pic fin 2013, époque à laquelle Gulp est venu lui grignoter une part de marché sans cesse croissante.
Broccoli reste à la marge, même s’il fait de temps en temps parler de lui. Et Glou n’a pas encore vraiment lancé son marketing, ses développeurs souhaitant lui donner encore un peu plus de polish avant de battre le rappel.
Et Brunch ? Brunch n’a jamais fait beaucoup de bruit. Il vit sa vie, la communauté de ses utilisateurs est extrêmement fidèle, et la grande majorité de ceux à qui on le montre sont vite convaincus : depuis près de 3 ans que je m’en sers dans mes formations JS (JS Guru puis JS Total et Node.js), c’est le premier truc que les apprenants veulent mettre en œuvre, de retour au boulot le lundi qui suit :-) Et chaque fois que je présente Dev Avengers, les gens ouvrent des yeux comme des ronds de flan…
Mais il reste plutôt discret. Avec environ 4 000 stars GitHub (44% de Grunt), 270 forks et 4 ans d’existence active, il est tout sauf faiblard, juste… discret.
Ceci dit, 2014 a commencé à voir une renaissance de Brunch dans l’esprit des développeurs. Divers articles voient le jour. 3 ans après sa naissance, les gens semblent soudain se rendre compte de sa présence. Par exemple :
Brunch is an ultra-fast HTML5 build tool http://t.co/jDhHaPPN2J
— Christian Heilmann (@codepo8) 21 Septembre 2014@tomdale skip the task runners and messy config files. plug-in based build tools ftw. http://t.co/6U0XV1GYMB
— Josh Habdas (@jhabdas) November 21, 2014
@Ken_Stanley Just discovered brunch.io today too which makes life even easier.
— Hugh Durkin (@hughdurkin) January 10, 2015
Il y a donc de l’espoir !
Personnellement, je l’utilise pour absolument tous mes builds front, du petit projet au gros mammouth, depuis 2012. Et toujours avec le même bonheur.
Avec cet article, je vais essayer de vous donner une bonne idée de ce qu’il a dans le ventre ; j’espère que ça vous donnera envie de l’essayer sur vos prochains projets, petits et grands. Si vous venez de Grunt ou Gulp, en particulier sur des besoins riches de build, ça risque de vous faire un choc :-)
Démarrer avec Brunch
Voyons tout ce que vous besoin de savoir pour utiliser agréablement Brunch dans vos projets, nouveaux comme existants.
Comme tous les outils cités plus haut, et comme une térachiée d’outils aujourd’hui, Brunch est basé sur Node.js et s’installe via npm. Vous pouvez choisir de l’installer en global, pour pouvoir utiliser la commande brunch depuis n’importe où :
npm install -g brunch…mais je vous recommanderais de l’installer aussi localement à votre projet courant, qui aura de toutes façons besoin d’un package.json pour fonctionner (au même titre que les autres outils évoqués dans cet article). Ainsi, vous pouvez utiliser plusieurs versions distinctes d’un projet à l’autre, sans conflits. Ce qui est bien, c’est que la commande brunch installée en global utilisera intelligemment la version locale à votre projet en interne, on a donc le meilleur des deux mondes !
Faut-il partir d’un squelette ?
Brunch met en avant la notion de squelette. Contrairement à des générateurs comme ceux associés à Yeoman, il s’agit là simplement de dépôts Git proposant une infra par défaut pour une application front utilisant Brunch. Il en existe un certain nombre, dont l’intérêt principal est de fournir une base de départ en créant certains dossiers, en prédéfinissant les dépendances dans le package.json et en fournissant une configuration Brunch de départ.
Brunch propose une commande brunch new à laquelle on passe un dépôt GitHub (ou toute URL publique de dépôt Git), et un chemin de clonage éventuel. Ça se limite à un git clone suivi d’un npm install…
Je vous recommande plutôt de partir de zéro (ou de votre propre projet) et de mettre vos fichiers au point vous-mêmes, pour bien maîtriser ce que vous faites.
Conventions et valeurs par défaut
Les docs officielles expliquent bien les bases et conventions pré-établies. La quasi-totalité peut être modifiée en configuration, pour s’adapter à vos besoins spécifiques d’architecture.
Gardez donc à l’esprit que ce que je décris dans cette section constitue le fonctionnement par défaut, mais pas une obligation. Ceci dit, plus vous suivrez ces conventions, moins vous aurez de code/configuration à créer et maintenir pour bénéficier des services de Brunch.
Je vous préciserai à chaque fois, de façon succincte, les éléments de ligne de commande ou de configuration qui permettent de quitter ces conventions ; pour tous les détails, cette page est votre amie.
Traitements prédéfinis
Brunch va s’occuper en tous les cas de :
- Concaténer les fichiers, par catégorie, vers une ou plusieurs destinations que vous définissez ;
- Déposer les résultats dans un dossier cible, accompagnés de fichiers et répertoires statiques que vous auriez posés au bon endroit source ;
- Enrober ceux de vos JS sources qui le prévoient en modules CommonJS (pendant la phase de concaténation) ;
- Produire les source maps nécessaires pour pouvoir déboguer dans votre navigateur sur base des contenus d’origine, non des concaténations ;
- Surveiller vos fichiers et dossiers sources pour réaliser une mise à jour incrémentale du build à la moindre modification (si vous le lancez en mode surveillance plutôt qu’en build unique) ;
- Fournir un serveur HTTP statique mais malin pour vos fichiers (si vous lui demandez).
La nature exacte des fichiers concaténés dépend des plugins installés, en revanche. Voyons déjà ces aspects « par défaut » un peu plus en détail.
Fichiers de configuration
Brunch va rechercher son fichier de configuration parmi les noms suivants, dans cet ordre :
brunch-config.coffeebrunch-config.js
On note une préférence pour CoffeeScript (Brunch est écrit en CoffeeScript, et transpilé en JS à chaque release) ; historiquement, il cherchait des fichiers config.*, mais c’est vite devenu un peu trop générique, donc il préfère désormais le nom plus spécifique.
Si vous ne connaissez pas CoffeeScript, ne paniquez pas : la quasi-totalité du temps, vous n’aurez qu’un gros objet (type JSON) à y mettre, et CoffeeScript vous épargnera « juste » le bruit des accolades, virgules et guillemets. On dirait du YAML, c’est tout propre et concis :-)
+Personnalisation : une option de ligne de commande vous permettait d’indiquer le fichier de configuration, mais elle a été dépréciée au profit d’un fichier unique avec des ajustements par environnement, une technique que nous illustrerons dans un chapitre ultérieur.
Dossiers
Brunch fait par défaut attention aux dossiers suivants :
appcontient toute la partie source, à l’exception des fichiers JS fournis par des tiers et non conçus pour être enrobés en modules. On y trouverait donc, dans les sous-dossiers de votre choix (ou à mêmeapp), des fichiers scripts, feuilles de style, et fichiers templates.- Tout dossier
assets(généralement justeapp/assets) verra son contenu copié-collé (récursivement) dans le dossier cible, tel quel, sans aucun traitement. - Tout dossier
vendor(généralement à côté du dossierapp) sera concaténé commeapp, à un gros détail près : les fichiers scripts ne seront pas enrobés en modules. On y met donc généralement les bibliothèques tierces 100% front qui n’auraient pas de chargeur intégré type UMD, ou simplement que notre code utilise encore (pour le moment ;-)) comme un bon vieux global, au lieu de faire desrequire(…). - Tout fichier démarrant par un underscore (
_) est considéré comme un fichier partiel, inclus par un autre, et ne sera pas utilisé de façon autonome. publicest le dossier cible par défaut. On retrouve là la convention de nombre de micro-serveurs type Rack et consorts.
Les dossiers app, vendor et public sont exprimés en relatif vis-à-vis du fichier de configuration de Brunch.
Personnalisation : les chemins sources sont modifiables avec un tableau de noms/chemins dans le réglage paths.watched. Le dossier cible est défini par paths.public. Les chemins à traitement spécial sont définis par conventions.assets et conventions.vendor (regex ou fonctions). Les fichiers à ignorer sont définis par conventions.ignored.
Enrobage CommonJS
Les modules, c’est le bien. Si vous en êtes encore à empiler les globales sans dépendances formelles, il est plus que temps de rattraper le train… Voilà six ans qu’on prêche les modules, il y a même eu une espèce de guerre des formats qui a abouti aux modules natifs dans ES6, lesquels ressemblent davantage au format CommonJS couramment utilisé par Node.js qu’à ce bon vieux AMD, qui est en nette perte de vitesse…
Les signes ne trompent pas : d’un côté, le passage aux modules ES6 natifs pour des projets ambitieux comme Ember 2 et Angular 2, de l’autre le succès phénoménal du JS isomorphique et d’outils comme Browserify, qui packagent du code « façon Node » (et même quelques modules Node.js noyau) pour une exécution dans le navigateur.
Par défaut, Brunch enrobe tous vos fichiers scripts qui ne sont pas à l’intérieur d’un dossier vendor comme des modules CommonJS : vous y êtes donc dans une closure (toutes vos déclarations explicites, et notamment var et function, sont donc privées), vous avez le droit (je dirais même le devoir !) d’y coller un bon gros "use strict"; en tête de fichier sans craindre de casser des scripts tiers, et vous avez accès à exports, module.exports et require().
Personnalisation : modules.wrapper et modules.definition définissent le type d’enrobage (sachant qu’on peut désactiver l’enrobage, point barre), tandis que modules.nameCleaner construit les noms des modules à partir des chemins des fichiers.
Sourcemaps
Toute concaténation, minification ou autre forme de traitement entre les fichiers sources et les productions déposées dans le dossier cible fait l’objet d’un suivi de débogage par source map.
Chaque fichier cible est accompagné d’une source map v3 multi-niveaux qui permettra aux outils de développement du navigateur (entre autres) d’afficher et de déboguer les fichiers sources en tout début de chaîne de build, et non les fichiers cibles réellement utilisés par la plate-forme.
Indispensable pour un débogage sain.
Personnalisation : le réglage sourceMaps peut désactiver, ou modifier, la génération des source maps. Mais quelle drôle d’idée !
Surveillance des sources
Brunch est, de base, capable de surveiller vos fichiers et dossiers sources pour, en cas de modification, mettre automatiquement à jour les fichiers produits. Cette mise à jour est incrémentale et très performante. Brunch affiche un message détaillé sur les fichiers sources détectés, les fichiers finaux mis à jour, et le temps que ça a pris.
Remarquez toutefois que cette surveillance n’est pas toujours parfaitement fiable sur Windows, et plus rarement Linux ou OSX (en tout cas jusqu’en 1.7.20 ; la prochaine version devrait avoir amélioré les choses). Certains réglages permettent de réduire ces faux-pas éventuels à presque rien, nous y reviendrons.
Cette surveillance a lieu en utilisant la commande brunch watch plutôt que le simple brunch build.
Au passage, il est également possible d’être notifié (par Growl (OSX/Windows) ou votre centre de notifications système OSX / Ubuntu) lors d’une erreur (par défaut) ou d’autres niveaux (avertissement, info), pour ne même pas avoir à regarder le terminal.
Personnalisation : le réglage fileListInterval indique le temps minimum entre deux détections. Le réglage watcher.usePolling change le substrat technique de la détection de changement vers un mode technique très légèrement plus lent, mais parfois plus fiable. Le réglage notifications permet de désactiver les notifications, ou de choisir les niveaux signalés.
Serveur web intégré
Brunch peut fournir un serveur HTTP statique pour vos fichiers produits, ce qui permet de tester en HTTP et non en fichiers simples. Il faut que Brunch tourne, ce qui implique qu’on est en mode watcher. Nous verrons les détails de ce serveur tout à l’heure, et notamment comment écrire le nôtre si besoin, mais voici quelques infos sur celui par défaut, obtenu en faisant brunch watch --server :
- Écoute en HTTP sur le port 3333, avec
/mappé sur le dossier public. - Charge automatiquement
index.htmlsur une URL de dossier ou un chemin inconnu (afin d’autoriser dupushStatecôté client, notamment). - Envoie les en-têtes CORS.
Personnalisation : Le réglage server est un objet permettant soit de modifier tous ces comportements, soit d’indiquer carrément un module serveur personnalisé. L’option de ligne de commande -p (ou --port) permet de changer le port d’écoute par défaut.
Chargement des plugins
Nous y reviendrons, mais pour utiliser un plugin dans Brunch, il suffit de l’installer avec npm : sa simple présence dans node_modules et dans package.json suffira à ce qu’il soit recensé, chargé et initialisé par Brunch, et il sera automatiquement employé pour les fichiers et environnements envers lesquels il se sera enregistré au démarrage.
La majorité des plugins Brunch sont conçus pour être opérationnels sans configuration particulière.
Personnalisation : on peut choisir les plugins à (dés)activer au travers des réglages plugins.on, plugins.off et plugins.only, et affiner la configuration des plugins via les têtes de réglages plugins.<name>.
Partir de zéro
Vous avez lu jusqu’ici ? Bravo ! Allez, maintenant, on fait du code !
Envie de suivre facilement ? J’ai préparé un dépôt avec toutes les étapes ci-après faciles à examiner / utiliser :
- Le dépôt GitHub
- Les archives, pour ceux qui n’utilisent pas Git : Zip ou TGZ.
Voyons un premier exemple, où nous resterions dans les conventions Brunch, mais sans partir d’un générateur. On va commencer avec juste du JS (ES3/ES5), des styles via SASS, et un HTML statique.
On va donc opter pour l’arborescence de départ suivante :
.
├── app
│ ├── application.js
│ ├── assets
│ │ └── index.html
│ └── styles
│ └── main.scss
└── package.json
Voici les fichiers de départ :
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Simple Brunch Demo</title>
<link rel="stylesheet" href="app.css">
</head>
<body>
<h1>
Brunch
<small>• A simple demo</small>
</h1>
<p>Lorem ipsum dolor sit amet, consectetur adipisicing elit.</p>
<script src="app.js"></script>
<script>require('application').init();</script>
</body>
</html>$default-bg: white;
$default-text: black;
body {
font-family: Georgia, serif;
font-size: 16px;
background: $default-bg;
color: $default-text;
}
h1 {
font-size: 2em;
margin: 0.5em 0 1em;
& > small {
color: gray;
font-size: 70%;
}
}"use strict";
var App = {
init: function init() {
console.log('App initialized.');
}
};
module.exports = App;
{
"name": "simple-brunch",
"version": "0.1.0",
"private": true
}
On va maintenant « installer » Brunch et le jeu minimum de plugins nécessaires, en local :
$ npm install --save-dev brunch javascript-brunch sass-brunch
…
$ npm ls -depth=0
simple-brunch@0.1.0 …
├── brunch@1.7.20
├── javascript-brunch@1.7.1
└── sass-brunch@1.8.9Il nous faut à présent une configuration Brunch minimale. Un fichier de configuration Brunch est un module Node qui exporte une propriété config, laquelle a, au minimum, besoin de la propriété files pour connaître les concaténations à effectuer. Voici le nôtre :
module.exports = config:
files:
javascripts: joinTo: 'app.js'
stylesheets: joinTo: 'app.css'
Oui, c’est tout ! :-)
Allez, on tente un build. Depuis le dossier racine du projet, là où se trouve le brunch-config.coffee (au même niveau que app, donc), faites :
$ brunch build
25 Feb 17:07:20 - info: compiled 2 files into 2 files, copied index.html in 94msRemarquez le temps de build pour ce one-shot : 94 millisecondes. Et je suis sur un disque crypté à la volée.
Voyons ce qui a été généré dans public :
public/
├── app.css
├── app.css.map
├── app.js
├── app.js.map
└── index.html
Le contenu de assets/ est bien là (donc index.html), ainsi que les concaténations et leurs source maps. Voyons app.css :
/* line 4, stdin */
body {
font-family: Georgia, serif;
font-size: 16px;
background: white;
color: black; }
/* line 11, stdin */
h1 {
font-size: 2em;
margin: 0.5em 0 1em; }
/* line 15, stdin */
h1 > small {
color: gray;
font-size: 70%; }
/*# sourceMappingURL=app.css.map*/
Pas mal. Et dans app.js ? Ça commence par le bootstrapper de Brunch, qui fournit toute la mécanique de gestion de modules et de require() en un peu moins de 100 lignes, puis on trouve nos modules, correctement enrobés :
require.register("application", function(exports, require, module) {
"use strict";
var App = {
init: function init() {
console.log("App initialized");
}
};
module.exports = App;
});
//# sourceMappingURL=app.js.map
Comme notre JS est désormais modularisé, rien n’apparaît sur la console au chargement de la page : il va falloir requérir le module qui sert de point d’entrée à l’application.
Par défaut, les modules sont nommés d’après leur chemin au sein du chemin surveillé qui donne lieu à modularisation. Si on n’a qu’un chemin surveillé, celui-ci ne préfixe pas (c’est notre cas, on n’a que app de concerné). Si on en a plusieurs, ils préfixent le nom. L’extension n’est pas utilisée, afin de laisser toute liberté en termes de langage source.
Puisque nous avons un app/application.js, le nom du module, comme on peut le voir dans le code ci-dessus, est tout simplement "application". Donc, ajoutons ceci en bas du <body> de notre app/assets/index.html :
<script>require('application').init();</script>On relance le build (on verra le watcher tout à l’heure) :
$ brunch b # version courte de "build"Et à présent, si on rafraîchit :
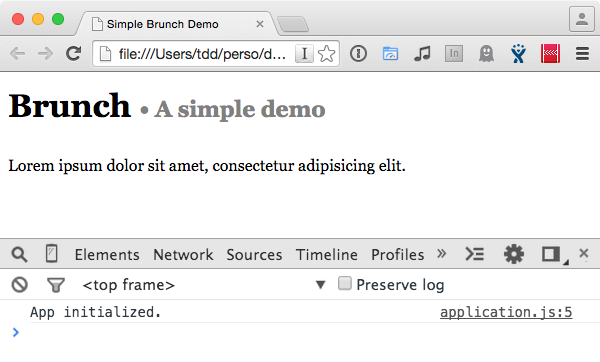
Remarquez le chemin indiqué dans la pile du log : application.js:5, et non app.js:98 : ce sont les source maps en action (si vous les avez activées dans les réglages de vos Dev Tools, ce que vous devriez !). Si vous avez ouvert la console après que le log a eu lieu, les source maps n’étaient pas encore chargées : ouvrez la console, puis rafraîchissez.
Même chose pour les CSS :
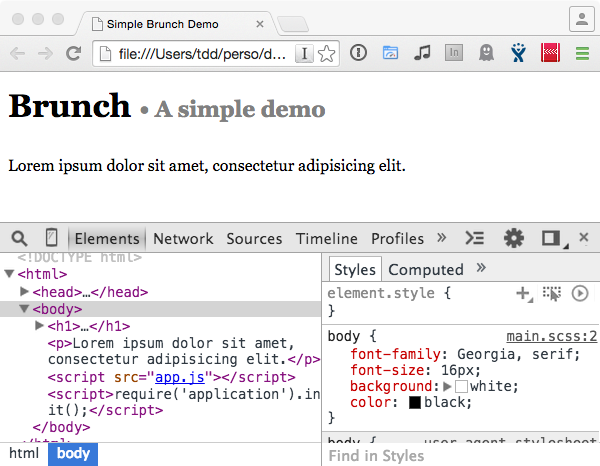
Vous voyez le main.scss:2 comme attribution de la règle body ? Et si vous cliquez dessus (ou dans les propriétés), vous irez bien sur le code source original.
Imaginons à présent que nous souhaitions utiliser jQuery, ou une autre bibliothèque. Si nous avons déjà du code qui suppose que jQuery est global, il nous faudra soit modifier notre code (indispensable à terme), soit ne pas enrober jQuery en module (acceptable en phase de transition).
Supposons que notre application.js attend en fait le chargement du DOM pour injecter son contenu en fin de <body> :
"use strict";
var App = {
init: function init() {
$('body').append('App initialized.');
}
};
module.exports = App;
On va d’abord employer la seconde approche, celle qui voudrait que jQuery reste disponible globalement, en transition. On pose donc notre jquery.js dans un nouveau dossier vendor, et on relance le build. Au rafraîchissement, ça fonctionne, le message apparaît en fin de document :
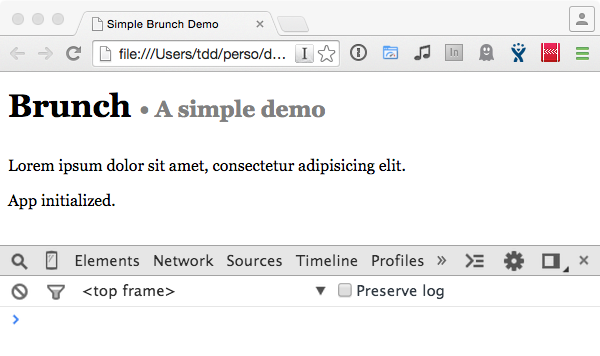
Le code complet de jQuery est en fait injecté tel quel entre le bootstrapper de Brunch et les codes enrobés en modules. Brunch va injecter là l’ensemble des fichiers des dossiers vendor dans l’ordre alphabétique (sauf à préciser des ajustements dans la configuration).
Mais tout de même, ce n’est pas terrible terrible, ce gros global dégueulasse qui traîne, là… D’autant que jQuery incorpore une sorte de chargeur UMD, capable de s’exporter correctement depuis un module CommonJS. Du coup, tentons plutôt de refactoriser notre code.
Déplaçons d’abord le jquery.js de vendor vers app, pour qu’il soit bien enrobé en module, et sous le nom simple jquery. Vous pouvez virer votre vendor vide si vous le souhaitez.
Puis, ajustons application.js pour requérir explicitement jQuery, tant qu’à faire sous le nom local $ (oui, local, souvenez-vous : on est dans un module, donc nos déclarations sont privées) :
"use strict";
var $ = require('jquery');
var App = {
init: function init() {
$('body').append('App initialized.');
}
};
module.exports = App;
On rebuilde, on rafraîchit, et ça marche toujours ! ❤️
Certains suggèrent de sortir les bibliothèques tierces du bundle principal, car nous allons les faire évoluer bien moins souvent que notre propre code : du coup, en proposant deux cibles, une pour les codes tiers, une pour le nôtre, on exige certes deux chargements au lieu d’un initialement, mais on fait recharger un bundle nettement plus petit par la suite.
Voici un exemple de configuration Brunch qui permet cela ; comme nos codes tiers ne sont pas ici regroupés dans un même dossier de base, mais juste posés à la racine du dossier surveillé pour que leurs noms de modules soient simples (on pourrait configurer ça autrement, on le verra), on va lister explicitement les modules concernés :
module.exports = config:
files:
javascripts: joinTo:
'libraries.js': /^app[\\\/]jquery\.js/
'app.js': /^(?!app[\\\/]jquery\.js)/
stylesheets: joinTo: 'app.css'
Dès qu’on a plusieurs cibles, nos joinTo deviennent des objets qui mettent en correspondance un nom de cible avec une description des sources. Ces descriptions sont des ensembles anymatch, à savoir des chemins spécifiques ou à base de globbing, des expressions rationnelles, des fonctions de prédicat, ou un tableau de ces composants (qui peuvent être mélangés). Bref, c’est super flexible.
Notez que pour que ça marche toujours, il faut ajuster le bas de notre app/assets/index.html :
<script src="libraries.js"></script>
<script src="app.js"></script>
<script>require('application').init();</script>
Utiliser des référentiels de modules tiers
Dans la pratique, ce qui est vraiment agréable pour les dépendances tierces, c’est de pouvoir s’appuyer sur des référentiels de modules existants. Côté front, on trouve essentiellement npm (valable pour Node.js et pour le front, et qui vient notamment de remplacer le référentiel officiel des plugins jQuery) et Bower (qui est, à mon humble avis, sur le départ, car npm est en train de le rendre obsolète).
Tout l’intérêt d’une gestion de dépendances formelle, c’est qu’on peut exprimer des dépendances flexibles sur les versions, et faciliter l’installation et la mise à jour des dépendances.
Brunch est en train de bosser dur pour nous fournir une intégration de tout premier ordre avec npm, ce qui facilitera le JS isomorphique et nous permettra d’exploiter nos installations node_modules de façon transparente dans notre code applicatif front. Pour le moment, en revanche, on est contraints de jouer avec le plugin pour Browserify.
En attendant, l’intégration Bower est déjà là. On aurait pu s’en servir pour jQuery, par exemple. Si nous utilisons le bower.json suivant pour décrire notre projet :
{
"name": "simple-brunch",
"version": "0.1.0",
"private": true,
"ignore": ["**/.*", "node_modules", "bower_components", "test", "tests"]
}
On installerait alors comme ceci :
$ bower install --save jquery#1.*
…
jquery#1.11.2 bower_components/jqueryOn peut désormais retirer le jquery.js de notre app. On va ajuster la configuration pour qu’elle colle toujours nos éléments dans deux cibles distinctes, sachant que les regexes de tout à l’heure ne sont plus adaptées :
module.exports = config:
files:
javascripts: joinTo:
'libraries.js': /^bower_components/
'app.js': /^app/
stylesheets: joinTo: 'app.css'
Qui plus est, c’est Bower, donc ça n’expose pas de modules (ಥ﹏ಥ). On ajuste notre app/application.js pour supposer à nouveau que $ est global, en retirant la ligne require(…) (bleuargh).
Puis on rebuilde, et ça marche !
Un petit coup de templating
Tout ça est déjà super cool, mais je m’en voudrais de ne pas vous faire une petite démo de templating, tant qu’à faire. Z’avez bien deux minutes ?
Le principe des plugins de templating de Brunch est simple :
- Les templates sont dans leurs propres fichiers, bien séparés du JS ;
- Ces fichiers sont précompilés par la techno de templating appropriée, pour produire une fonction JS prête à l’emploi : on lui file les données dynamiques sous forme d’un objet (souvent appelé presenter ou view model), elle retourne du HTML.
- Cette fonction est enrobée en module, comme d’hab ; c’est son export par défaut.
Cette approche nous évite de pourrir notre JS avec du code de templates, comme on le voit trop souvent à coup d’énormes String littérales, mais aussi évite de pourrir notre HTML à coup de templates injectés dans des balises de type <script type=“template/handlebars”>, ce qui m’a toujours semblé un gros hack dégueulasse. Ça nous laisse JSX, certes, mais même là, y’a une astuce… Un des intérêts côté éditeur, c’est qu’on a donc des fichiers dédiés aux templates, avec la bonne extension et la bonne coloration syntaxique.
On va utiliser Jade, parce que voilà, Jade, c’est sympa comme tout. Si vous faites plein de Ember à côté, jetez un œil à Emblem, aussi, c’est un peu leur fils caché à tous les deux.
Commençons par installer le plugin :
npm install --save-dev jade-brunchIndiquons ensuite à Brunch d’incorporer les modules résultats dans notre JS concaténé applicatif :
module.exports = config:
files:
javascripts: joinTo:
'libraries.js': /^bower_components/
'app.js': /^app/
stylesheets: joinTo: 'app.css'
templates: joinTo: 'app.js'
À présent ajoutons notre template, par exemple dans app/views/list.jade :
h2 Things to do:
ul#mainTodo.tasks
each item in items
li= item
L’utilisation au sein de notre application.js est super simple :
"use strict";
var App = {
items: ['Learn Brunch', 'Apply to my projects', '…', 'Profit!'],
init: function init() {
var tmpl = require('views/list');
var html = tmpl({ items: App.items });
$('body').append(html);
}
};
module.exports = App;
On builde, on ouvre public/index.html, et là…
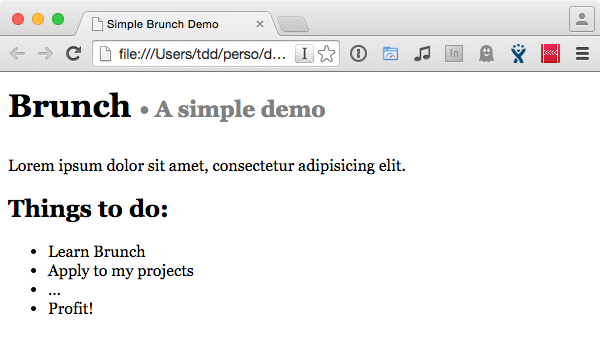
C’est pas un peu la grosse classe à Dallas ça Madame ?
Adapter Brunch à un projet existant
Supposons à présent que vous partiez d’un projet existant, dont vous souhaitez confier le build front à Brunch. Peut-être venez-vous de Grunt, ou Gulp, ou que sais-je… Peu importe. Il faut se poser quelques questions de base :
- Où sont les fichiers sources pour le build ?
- Quels langages utilisent-ils ?
- Dans quel dossier cible va le build ?
- Quel est le mapping source -> cible au sein du build ?
- Est-ce que je veux enrober mon JS applicatif en modules ?
Le point 1 détermine la valeur du réglage paths.watched, pour le ou les répertoires de base à exploiter/surveiller. La valeur par défaut est ['app', 'test', 'vendor'], mais il y a fort à parier que vous devrez changer ça. Autres réglages concernés : conventions.assets, qui va déterminer les dossiers dont le contenu sera copié-collé tel quel, et conventions.vendor, qui indique les dossiers dont le JS ne doit pas être enrobé en modules, s’il y en a (attention, si vous passez par Bower, les composants qu’il fournit ne sont jamais enrobés).
Le point 2 détermine les plugins Brunch à utiliser, sachant qu’on peut très bien mélanger les genres ; par exemple, quand j’utilise Bootstrap, je préfère largement utiliser son code source SASS, afin de facilement personnaliser le thème, notamment dans _variables.scss. Cependant, je préfère Stylus pour mes propres styles, j’ai donc souvent à la fois sass-brunch et stylus-brunch installés.
Si mon app utilise du MVC côté client, je vais toujours isoler mes templates dans leurs propres fichiers, et donc utiliser par exemple jade-brunch ou dust-linkedin-brunch pour les convertir de façon transparente en modules exportant une unique fonction de rendering qui résulte de la précompilation du template.
Le point 3 détermine la valeur du réglage paths.public, qui vaut par défaut 'public'. Ce dossier n’a pas besoin d’exister en début de build. Les fichiers cibles sont exprimés relativement à ce chemin de base.
Le point 4 gouverne la structure du réglage files, avec jusqu’à trois sous-sections :
javascripts: tout ce qui produit du JS à terme, hors pré-compilation de templates (statut spécial) ;stylesheets: tout ce qui produit du CSS à terme ;templates: tout ce qui concerne la précompilation de templates pour produire à chaque fois une fonction de rendering (avec un argument contenant le presenter, ou view model, et le HTML en valeur de retour synchrone). Souvent, la cible sera la même que pour la partie noyau dejavascripts.
Chacune de ces clés peut être très simple ou très avancée. Si on fournit juste un chemin de fichier (une String) comme valeur, tous les fichiers candidats iront vers cette unique concaténation. Si on fournit plutôt un objet, les clés sont les chemins cibles, et les valeurs, qui déterminent quelle portion de la codebase source va vers la cible, sont des ensembles anymatch, c’est-à-dire qu’il peut s’agir de :
- Une simple
String, qui devra correspondre au chemin exact du fichier, tel que perçu par Brunch (on y reviendra dans un instant) ; - Une expression rationnelle, qui devra correspondre au chemin du fichier ; très utile pour des préfixes, genre
/^app\//ou/^vendor\//; - Une fonction prédicat, qui prendra le chemin exact en argument et renverra de façon synchrone une valeur interprétée comme booléenne ;
- Un tableau de valeurs, qui peuvent chacune être un des types précédents.
C’est donc extrêmement flexible comme méthode de répartition entre les cibles (ou même si on n’a qu’une cible, mais qu’on veut filtrer ce qui y va).
Le point 5 ne devrait pas être une vraie question : bien sûr que vous devriez utiliser des modules. On est en 2015, bordel, faut sortir de la préhistoire et du code bordélique, les gens ! Et tant qu’à faire, vous devriez opter pour CommonJS jusqu’à nouvel ordre (ce qui facilite le JS isomorphique et la migration ultérieure vers des modules natifs ES6).
Ça se définit avec les réglages modules.wrapper et modules.definition. Si vous avez décidé de rester en mode porcherie, vous pouvez les mettre tous les deux à false. Si vous croyez encore en AMD (ou que la Terre est plate), vous pouvez mettre amd. Il est même possible de fournir des fonctions de personnalisation pour des systèmes plus exotiques. Par défaut, les deux valent commonjs.
Un dernier point, si vous recourez aux modules (bravo !), est le nom de ces modules. Par défaut, il reprend le chemin exact vu par Brunch, moins le préfixe app/ si vous êtes restés sur les chemins sources conventionnels. Si vous avez plusieurs racines personnelles définies dans paths.watched, celles-ci restent comme préfixes. Dans tous les cas, l’extension du fichier dégage.
Si cela vous dérange, par exemple parce que vous voulez isoler les bibliothèques tierces dans app/externals/, et préserver leurs noms longs par-dessus le marché (genre jquery-1.11.2-min.js et moment-2.2.1-fr.js), mais voulez conserver des noms de modules simples ("jquery" et "moment"), vous devrez fournir une fonction de calcul de nom de module personnalisée, via le réglage modules.nameCleaner. Par exemple, dans notre formation JS Total, qui a exactement ce cas de figure, on trouve le réglage suivant :
modules:
nameCleaner: (path) ->
path
# Strip app/ and app/externals/ prefixes
.replace /^app\/(?:externals\/)?/, ''
# Allow -x.y[.z…] version suffixes in mantisses
.replace /-\d+(?:\.\d+)+/, ''
# Allow -fr lang suffixes in mantisses
.replace '-fr.', '.'Builds de développement et de production
Par défaut, Brunch s’exécute en environnement de développement. Cela signifie notamment que les plugins de minification (JS ou CSS) ne sont pas appliqués (le réglage optimize vaut par défaut false en environnement de développement ; on peut bien sûr le changer).
L’environnement est précisé en ligne de commande, par l’option -e ou --env, à laquelle on passe le nom de l’environnement. On peut avoir tous les environnements qu’on veut, sachant que production est une valeur prédéfinie (avec son option dédiée, -P ou --production, qui équivaut à --env production), notamment parce qu’elle recale par défaut optimize à true.
Mais surtout, on peut modifier les réglages pour des environnements précis, au moyen de la clé racine overrides. On précise en-dessous le nom de l’environnement, et à l’intérieur de celui-ci, des remplacements pour tout réglage où on le juge nécessaire. La doc officielle donne un exemple qui reflète en fait les réglages par défaut de production :
overrides:
production:
optimize: true
sourceMaps: false
plugins: autoReload: enabled: falsePersonnellement j’aime les sourcemaps même en production, du coup je définirais plutôt ceci dans ma configuration :
overrides:
production:
sourceMaps: trueWatcher
Depuis le début de cet article, on rebuilde manuellement à chaque fois. D’accord, ça va vite, mais quand même. Dans la vraie vie, on préfère avoir un watcher qui surveille notre codebase source et met à jour, le plus vite possible, notre build.
C’est là quelque chose où Brunch excelle. Il incorpore de base un watcher incrémental très performant. Au lieu de lancer brunch build toutes les quinze secondes, lancez une seule fois brunch watch. Puis faites quelques modifs à vos fichiers et sauvez à chaque fois. Voyez ce à quoi ça ressemble pour notre démo :
$ brunch watch # Ou brunch w, pour les flemmasses
26 Feb 16:46:42 - info: compiled 3 files into 3 files, copied index.html in 304ms
26 Feb 16:47:01 - info: compiled application.js into app.js in 69ms
26 Feb 16:47:10 - info: copied index.html in 72ms
26 Feb 16:47:14 - info: compiled main.scss into app.css in 71msBrunch a modifié vers sa version 1.7.0 sa couche de surveillance interne, chokidar, et utilise désormais un intervalle de vérification minimal pour réduire la charge, et cet intervalle est par défaut à 65ms. Si je voulais la jouer agressif et réglais fileListInterval à 20, par exemple, ça donnerait ça :
$ brunch watch
26 Feb 16:49:31 - info: compiled 3 files into 3 files, copied index.html in 266ms
26 Feb 16:49:36 - info: compiled application.js into app.js in 26ms
26 Feb 16:49:43 - info: copied index.html in 25ms
26 Feb 16:49:44 - info: compiled main.scss into app.css in 26msMais en vrai, 65ms, c’est très raisonnable, hein… :-) Vous vous dites peut-être que là, notre codebase est ridicule, c’est normal que ça aille si vite (même si Grunt et Gulp seraient déjà allègrement à 1000 voire 2000ms). Okay, prenons la codebase d’exemple de notre formation JS Total :
app
├── application.js
├── assets
│ ├── apple-touch-icon-114x114.png
│ ├── apple-touch-icon-120x120.png
│ ├── apple-touch-icon-144x144.png
│ ├── apple-touch-icon-57x57.png
│ ├── apple-touch-icon-60x60.png
│ ├── apple-touch-icon-72x72.png
│ ├── apple-touch-icon-76x76.png
│ ├── apple-touch-icon-precomposed.png
│ ├── apple-touch-icon.png
│ ├── favicon-16x16.png
│ ├── favicon-196x196.png
│ ├── favicon-32x32.png
│ ├── favicon-96x96.png
│ ├── favicon.ico
│ ├── fonts
│ │ ├── glyphicons-halflings-regular.eot
│ │ ├── glyphicons-halflings-regular.svg
│ │ ├── glyphicons-halflings-regular.ttf
│ │ └── glyphicons-halflings-regular.woff
│ ├── images
│ │ └── spinner.gif
│ ├── index.html
│ ├── mstile-144x144.png
│ ├── mstile-150x150.png
│ ├── mstile-310x150.png
│ ├── mstile-310x310.png
│ └── mstile-70x70.png
├── bootstrap.js
├── externals
│ ├── backbone-1.0.0.js
│ ├── backbone-mediator.js
│ ├── backbone-stickit-0.8.0.js
│ ├── bootstrap
│ │ ├── collapse.js
│ │ ├── modal.js
│ │ ├── tooltip.js
│ │ └── transition.js
│ ├── console-helper.js
│ ├── jquery-1.10.2.js
│ ├── lawnchair-dom.js
│ ├── lawnchair.js
│ ├── moment-2.2.1-fr.js
│ ├── socket.io.js
│ └── underscore-1.6.0.js
├── initialize.js
├── lib
│ ├── appcache.js
│ ├── connectivity.js
│ ├── location.js
│ ├── notifications.js
│ ├── persistence.js
│ ├── places.js
│ ├── router.js
│ └── view_helper.js
├── models
│ ├── check_in.js
│ ├── check_in_ux.js
│ └── collection.js
├── styles
│ ├── check_in.styl
│ ├── history.styl
│ ├── main.styl
│ └── places.styl
└── views
├── check_in_details_view.js
├── check_in_view.js
├── history_view.js
├── home_view.js
├── templates
│ ├── _layout.jade
│ ├── _mixins.jade
│ ├── check_in.jade
│ ├── check_in_details.jade
│ ├── check_ins.jade
│ ├── history.jade
│ ├── home.jade
│ └── places.jade
└── view.js
vendor
└── styles
└── bootstrap
├── _alerts.less
├── _badges.less
├── _breadcrumbs.less
├── _button-groups.less
├── _buttons.less
├── _carousel.less
├── _close.less
├── _code.less
├── _component-animations.less
├── _dropdowns.less
├── _forms.less
├── _glyphicons.less
├── _grid.less
├── _input-groups.less
├── _jumbotron.less
├── _labels.less
├── _list-group.less
├── _media.less
├── _mixins.less
├── _modals.less
├── _navbar.less
├── _navs.less
├── _normalize.less
├── _pager.less
├── _pagination.less
├── _panels.less
├── _popovers.less
├── _print.less
├── _progress-bars.less
├── _responsive-utilities.less
├── _scaffolding.less
├── _tables.less
├── _theme.less
├── _thumbnails.less
├── _tooltip.less
├── _type.less
├── _utilities.less
├── _variables.less
├── _wells.less
└── bootstrap.less
Aaaah, on fait moins les malins là, hein !? :-) Eh bah, voyez ce que ça donne (intervalle par défaut à 65ms) :
$ brunch watch
… 16:54:10 - info: compiled 46 files and 1 cached into 2 files, copied 25 in 1246ms
… 16:54:37 - info: compiled application.js and 41 cached files into app.js in 255ms
… 16:54:45 - info: compiled history.styl and 4 cached files into app.css in 157ms
… 16:55:03 - info: copied index.html in 67msAlors oui, pour les builds JS et CSS, on est passés à « carrément » 200ms en moyenne, mais c’est surtout parce qu’on a une tonne de bibliothèques JS lourdes (jQuery 1.11, etc.), et du CSS lourd (tout Bootstrap 3), ce qui fait que même en incrémental, on écrit nettement plus gros sur le disque :
$ ls -lah public/*.{js,css}
-rw-r--r-- 1 tdd staff 119K fév 26 16:54 public/app.css
-rw-r--r-- 1 tdd staff 709K fév 26 16:54 public/app.jsTiens, profitons-en pour tester la minification :
$ brunch build --production
…
$ ls -lah public/*.{js,css}
-rw-r--r-- 1 tdd staff 97K fév 26 16:57 public/app.css
-rw-r--r-- 1 tdd staff 252K fév 26 16:57 public/app.jsNettement mieux.
Attention, il arrive hélas fréquemment sur Windows (notamment depuis cette mise à jour de chokidar, que j’ai évoquée plus haut) que les nouveaux fichiers soient mal détectés, voire que certaines modifs passent à la trappe. Plus rarement, je l’ai vu arriver sur Linux voire OSX. Il semble qu’activer le réglage watcher.usePolling (à true, donc) résolve la majorité de ces problèmes (mais pas tous…). Ça devrait s’améliorer considérablement avec la 1.8 à venir…
Serveur web, intégré ou personnalisé
Comme je l’ai signalé plus haut, le watcher permet aussi de lancer en parallèle un serveur web pour servir les fichiers produits. Certaines technologies ont besoin que la page soit servie en HTTP(S), et une simple ouverture du fichier dans le navigateur ne suffit pas. Ça permet aussi des URLs plus courtes…
Il existe deux manières de lancer ce serveur :
- Explicitement dans la ligne commande :
brunch watch --server,brunch watch -svoirebrunch w -ssi on a bien la flemme ; - Via les réglages
serverdubrunch-config.coffee.
Le serveur par défaut est fourni en fait par le module npm pushserve, et fournit donc un peu plus qu’un bête serveur statique : il offre une gestion CORS, un routage systématique pour faciliter le recours à l’API pushState, etc.
Si vous souhaitez toujours lancer ce serveur quand le watcher démarre, il vous suffit de rajouter à la configuration le réglage suivant :
server:
run: yesSi vous voulez un port différent de 3333, renseignez aussi, dans server, un réglage port avec le numéro.
Écrire notre propre serveur
Il n’empêche, parfois votre micro-serveur a besoin de fonctionnalités en plus, ne serait-ce que pour une démo ou une formation… Voyons comment réaliser notre propre serveur, qui fournirait en plus deux points d’accès REST :
- POST sur
/itemsavec un champtitleajoute une entrée. - GET sur
/itemsrenvoie la liste des entrées.
Nous allons rester simples et utiliser ce bon vieux Express, avec le minimum de modules pour fournir notre service.
On fournit un serveur personnalisé à Brunch en renseignant le réglage server.path, qui indique un module à vous. Ce module doit exporter une fonction startServer(…) avec la signature suivante :
startServer(port, path, callback)Lorsque votre serveur a fini de démarrer, il appelle callback(…) pour que Brunch reprenne la main. Le serveur est automatiquement arrêté quand le watcher de Brunch s’arrête.
Voici notre serveur d’exemple. Il aurait pu être écrit en CoffeeScript, mais pour rester accessible à la totalité de mes lecteurs, le voici en JS :
'use strict';
var bodyParser = require('body-parser');
var express = require('express');
var http = require('http');
var logger = require('morgan');
var Path = require('path');
// Notre fonction de démarrage serveur
exports.startServer = function startServer(port, path, callback) {
var app = express();
var server = http.createServer(app);
// Stockage en mémoire des entrées gérées via REST
var items = [];
// Middlewares de base : fichiers statiques, logs, champs de formulaire
app.use(express.static(Path.join(__dirname, path)));
app.use(logger('dev'));
app.use(bodyParser.urlencoded({ extended: true }));
// GET `/items` -> JSON du tableau des entrées
app.get('/items', function(req, res) {
res.json(items);
});
// POST `/items` -> Ajout d’une entrée d’après le champ `title`
app.post('/items', function(req, res) {
var item = (req.body.title || '').trim();
if (!item) {
return res.status(400).end('Nope!');
}
items.push(item);
res.status(201).end('Created!');
})
// Mise en écoute du serveur sur le bon port, notif à Brunch une fois
// prêts, grâce à `callback`.
server.listen(port, callback);
};
Pour que ça marche, on prend soin d’ajouter les modules nécessaires à notre package.json :
$ npm install --save-dev express body-parser morganPuis on modifie notre configuration, en rendant le serveur automatique tant qu’à faire :
server:
path: 'custom-server.js'
run: yes
Tentez un watcher :
$ brunch w
02 Mar 12:45:04 - info: starting custom server
02 Mar 12:45:04 - info: custom server started, initializing watcher
02 Mar 12:45:04 - info: compiled 3 files into 3 files, copied index.html in 269msRemarquez les infos sur le serveur personnalisé. Tentez un accès à localhost:3333 désormais : ça marche ! Histoire de tester ça, modifions notre application.js :
"use strict";
var count = 0;
var App = {
items: ['Learn Brunch', 'Apply to my projects', '…', 'Profit!'],
init: function init() {
var tmpl = require('views/list');
var html = tmpl({ items: App.items });
$('body').append(html);
$.each(App.items, function(i, item) { requestItem(item); });
}
};
function requestItem(item) {
$.ajax('/items', {
type: 'post',
data: { title: item },
success: function(res) {
console.log('Successfully posted entry “' + item + '”: ' + res);
if (++count === App.items.length) {
$.getJSON('/items', function(res) {
console.log('Successfully fetched back entries:', res);
});
}
}
});
}
module.exports = App;
Le watcher récupère notre mise à jour, et si nous rafraîchissons la page et que nous examinons la console, nous voyons ceci :
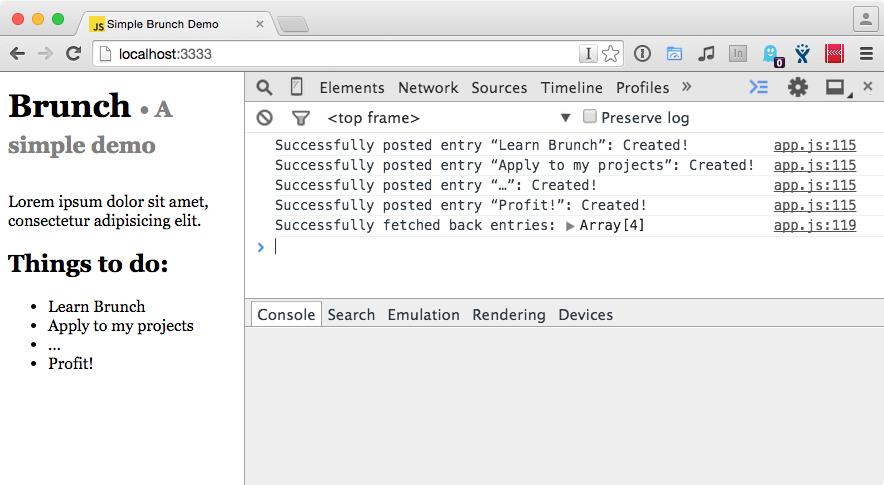
Tout roule ! (づ ̄ ³  ̄)づ
Et on n’est pas obligés de le faire en Node…
Un dernier réglage serveur qui mérite d’être mentionné : server.command, qui remplace en fait tous les autres réglages de server. Il vous permet de spécifier une ligne de commande qui lancera votre serveur personnalisé, lequel peut donc utiliser une autre technique que Node, telle que PHP, Ruby ou Python… Vous pourriez par exemple utiliser un truc de ce genre :
server:
command: "php -S 0.0.0.0:3000 -t public"Des plugins pour tous les besoins de build
Dans Brunch, la répartition des tâches est assez différente de celle qu’on trouve dans Grunt, Gulp, etc. Beaucoup de fonctionnalités et comportements sont inclus de base (pipeline de build, watcher incrémental, source maps, etc.), mais le reste appartient en effet à des plugins, y compris la prise en charge de chaque langage source.
On utilise en général au moins un plugin pour les fichiers de scripts, un pour ceux de styles, et un minifieur pour chaque format.
Le site officiel en recense pas mal, selon les pull requests de leurs auteurs, mais il y en a en fait beaucoup plus ; nous allons parcourir les principaux ci-dessous.
Note : dans tout le texte qui suit, les noms de plugins sont des liens vers leur descriptif sur npm.
Activation d’un plugin
Pour qu’un plugin soit actif et utilisé, il suffit qu’il soit installé, donc qu’il figure au package.json et ait été installé par npm ensuite.
Brunch inspecte en fait les modules ainsi installés à la recherche de tous ceux dont l’export par défaut est un constructeur dont le prototype a une propriété brunchPlugin à true.
Il instancie alors automatiquement le plugin avec la configuration générale en argument, et l’enregistre en fonction de son type de fichier pris en charge, s’il en indique un (via ses propriétés type et extension).
Bref, oubliez les loadNpmTasks et autres blagues du genre.
Affinage éventuel par configuration
Chaque plugin est normalement conçu pour être opérationnel et utile sans configuration spécifique ; mais il reste possible d’affiner leur comportement via une configuration dédiée. Celle-ci est dans le brunch-config.coffee, sous la clé plugins et la sous-clé définie par le plugin.
Par exemple, le
plugin appcache-brunch lit plugins.appcache. Le plus souvent, les noms
de clé sont triviaux à deviner, mais ça peut varier… Ainsi, browser-sync-brunch lit plugins.browserSync. Consultez la doc du plugin pour être sûr-e !
Brunch et les CSS
Les plugins orientés CSS ont sur leur prototype le type "stylesheet", et généralement une valeur spécifique pour extension. Ce sont principalement des transpilers, ce que Brunch appelle génériquement des compilers. À l’heure où j’écris ces lignes, on trouve notamment :
css-brunch, pour la gestion des CSS « nues » (celles du W3C) ;cssnext-brunch, qui vise les évolutions en cours (CSS4+, etc.) grâce à cssnext ;less-brunchetsass-brunch, évidemment, ainsi quecompass-brunchqui délègue à Compass pour ceux qui aiment les trucs un peu… euh… lourds ?!stylus-brunchpour Stylus, mon p’tit chéri ;- Divers outils essaient de jouer les couteaux suisses à CSS ; on trouve des plugins pour eux, par exemple
rework-brunchpour rework,pleeease-brunchpour pleeease ou encorepostcss-brunchpour PostCSS. autoprefixer-brunchse concentre sur l’auto-préfixage des règles à l’aide du bien-nommé autoprefixer, qui fait justement partie de PostCSS.- Côté coding style, CSSComb est sympa, et dispose évidemment de plugins pour les builders, dont
csscomb-brunch.
Brunch et JavaScript
Paysage similaire aux CSS, mais pour un type valant "javascript". Je vous parlerai des linters plus loin, mais côté transpilers, on est déjà grave servis :
javascript-brunchpour du JS « nu » (ES3/5, standards ECMA-262) ;coffee-script-brunch, évidemment, eticed-coffee-script-brunchpour les têtes brulées ;json-brunch, pour utiliser directement des fichiers JSON comme modules ;- dans le même univers, mais infiniment moins usité, on trouvera
LiveScript-brunchpour LiveScript,ember-script-brunchpour le plutôt niche EmberScript,roy-brunchpour le encore plus niche Roy ettypescript-brunchpour le déjà nettement plus populaire TypeScript (David & David, c’est vous que je regarde !). - Plus subtils :
wisp-brunchqui gère Wisp, une sorte de ClojureScript, etsweet-js-brunchqui donne accès aux merveilles des « macros hygiéniques » de sweet.js.
Et parce qu’on est quand même en 2015, hein, on trouve aussi une gestion automatique des JSX de React et plusieurs voies pour ES6 :
react-brunchqui auto-compile les.jsxvia React ;es6-module-transpiler-brunchpour gérer seulement la syntaxe de modules d’ES6 (c’est l’avenir !) ;traceur-brunchetbabel-brunchpour accéder à un maximum d’ES6. Actuellement, Babel (anciennement 6to5 + CoreJS) a nettement l’avantage côté taux de prise en charge du standard, et en plus, il intègre directement JSX !
Brunch et les templates
Après les scripts et les styles, la troisième catégorie de fichiers qui bénéfice d’une gestion spécifique par Brunch, ce sont les templates.
Pour rappel, lorsque Brunch a un plugin pour ça, il s’agit d’un compiler qui va précompiler le template pour produire un module exportant une unique fonction prête à l’emploi : on ne paie donc pas une pénalité d’analyse à l’exécution. Cette fonction reçoit un objet dont les propriétés sont exploitables dans le template comme des variables : ce qu’on appelle traditionnellement un presenter ou view model. La fonction retourne le HTML résultat.
Et côté langages de templates, on a vraiment l’embarras du choix :
- Les grands classiques :
handlebars-brunchet une spécialisationember-handlebars-brunch, évidemment ;hoganjs-brunch, si vous préférez Hogan, une alternative courante ;jade-brunchpour mon chéri Jade et même une spécialisationjade-angularjs-brunch, qui produit un module AngularJS plutôt.
- L’ultra-puissant Dust est également bien représenté via
dustjs-linkedin-brunchpour l’extension Dust maintenue par LinkedIn, qui est notamment utilisée par PayPal, aussi… - Un type a sorti
jade-react-brunch, qui me permet d’éviter JSX et de continuer à utiliser la syntaxe Jade dans un fichier distinct, et ça me pond un module exportant une fonction qui utilise le builderReact.DOM… Ça me fait saliver, ça ! - Ensuite, toute la série des syntaxes un peu plus niches, en tout cas pour du templating :
eco-brunchpour Eco, une syntaxe de type ERB basée sur CoffeeScript ;emblem-brunchpour Emblem, similaire à Jade mais avec beaucoup de syntaxes confortables pour Ember et les habitués d’Handlebars ;markdown-brunchetyaml-front-matter-brunch, qui du coup ressemble à du Jekyll ;swig-brunchpour Swig, à l’attention des fans de Django ;ractive-brunchpour RactiveJS ;nunjucks-brunchpour Nunjucks, et enfinhtml2js-brunchpour HTML2JS.
- Il y a également des plugins qui compilent « statiquement » : c’est juste quand, au lieu de faire un asset statique HTML, vous préférez utiliser une syntaxe alternative, quitte à y injecter un presenter issu d’un fichier JSON, par exemple :
static-jade-brunch;static-underscore-brunch(pour le micro-templating d’Underscore.js).
Brunch et le workflow de développement
Aujourd’hui, le dev front, c’est compliqué. On utilise plein de technos, on veut continuer à pouvoir déboguer rapidement, avoir un feedback facile dans le navigateur, faire attention aux performances, etc.
Il existe plein d’outils pour nous aider, mais c’est la plaie de devoir les gérer chacun de son côté, les lancer à part, etc. Brunch peut nous aider, grâce à ses plugins d’intégration.
Les linters d’abord :
jshint-brunchévidemment, qui va exécuter JSHint avec nos réglages en vigueur (.jshintrcnotamment) sur tout notre code applicatif (par défaut,appdonc). Peut fonctionner en mode avertissement (dans le log, mais n’empêche pas le build) ou erreur (empêche le build). Exécuté en incrémental lors du watcher, aussi.coffeelint-brunchpour CoffeeLint, si vous faites du CoffeeScript.jsxhint-brunchpour JSXHint, capable d’exécuter JSHint sur du JSX sans se prendre les pieds dans le tapis.- Hélas pas d’intégration ESLint pour le moment, mais pourquoi ne pas la contribuer vous-même ?
- Pas d’intégration JSLint non plus, mais là je ne risque pas de chouiner…
Une boucle de feedback rapide est indispensable quand on fait du front, avec la capacité notamment à voir tout de suite le résultat de nos travaux CSS et JS dans le navigateur, voire les navigateurs, ouvert(s). On trouve quelques plugins pour ça, tous conçus pour fonctionner en mode watcher :
auto-reload-brunchréagit à tout changement en injectant les CSS à la volée si c’est là tout ce qui a bougé ; si du JS est impliqué, il recharge carrément la page. Ça utilise les Web Sockets uniquement, donc pour IE, il faut au moins la version 10.browser-sync-brunchenrobe l’excellent BrowserSync, qui permet d’injecter la CSS en direct (sans rechargement), mais aussi de synchroniser tout un tas de manips entre divers navigateurs ouverts sur la page : remplissage de formulaire, défilement, clics, etc. Très pratique pour tester du responsive simplement. (full disclaimer : je fais partie des mainteneurs du plugin).fb-flo-brunch, par votre serviteur, fournit une intégration de premier plan pour le génial fb-flo, jetez-vous dessus !
La documentation du code n’est pas oubliée : des intégrations regénèrent la doc au moment du build, pour vous épargner une ligne de commande.
jsdoc-brunchévidemment, mais aussi…docco-brunch, pour Docco, en mode code source annoté donc.- J’adorerais voir quelqu’un contribuer
groc-brunch, car Groc enterre Docco !
On trouve aussi toute une série de plugins conçus pour remplacer des mots-clés, marqueurs ou chaînes de traduction pendant le build :
process-env-brunchse base sur les variables d’environnement ;keyword-brunch(deux variantes) utilise la configuration générale pour déterminer sa table de correspondance et son comportement ;jspreprocess-brunchajoute un préprocesseur « façon C » (avec des directives#BRUNCH_IF, etc. dans des commentaires) qui permet de faire varier le code obtenu en fonction de la cible de compilation ;constangular-brunch, un peu dans le même esprit, injecte des configurations au format YAML dans votre application AngularJS sous forme d’un module dédié, de façon sensible à l’environnement (développement, production) ;yaml-i18n-brunch, plus spécialisé, convertit des fichiers YAML en fichiers JSON, en prenant soin de remplir les trous dans les locales dérivés à partir du locale par défaut.
Quelques autres plugins méritent d’être signalés :
dependency-brunchpermet d’exprimer des dépendances entre fichiers sources que Brunch n’a pas vu, de façon à ce qu’il recompile le nécessaire. Par exemple, si des vues Jade étendent un layout ou incluent des mixins, on peut exprimer ces dépendances pour que toucher au layout (ou aux mixins) recompile automatiquement les vues qui les utilisent.groundskeeper-brunchretire de vos fichiers JS tout ce qui peut gêner en production : appelsconsole, instructionsdebugger, blocs spécifiques… (à définir impérativement avant les minifieurs).after-brunchfournit une manière simple d’enregistrer des commandes (lignes de commande) à exécuter après un build, ce qui ouvre la porte à beaucoup de choses !
Brunch et la performance web
Brunch se soucie évidemment de vos perfs, et donc de produire des assets aussi optimisés que possible, tout en favorisant des technologies complémentaires. La plupart de ces plugins n’ont pas d’intérêt au watch, plus pour les builds one-shot de production.
Ça commence avec divers plugins autour des images :
retina-brunchdérive la version simple de toute image « déclarée Retina » (dotée d’un suffixe de mantisse@2x) ;sprite-brunchutilise Spritesmith pour produire une grosse image sprited et la feuille de style associée (SASS, LESS ou Stylus) à partir de vos images d’origine. Pas aussi puissant que Glue, mais costaud quand même.imageoptmizer-brunch(notez l’absence duicentral…) se déclenche en mode production / optimisation pour appliquer à vos images dans le dossier public, suivant ce que vous avez d’installé, JPEGTran, OptiPNG et SmushIt. Histoire de bien réduire les tailles.
On a bien sûr des minifieurs haut de gamme pour JS et CSS :
uglify-js-brunchutilise UglifyJS 2 pour compacter à mort les fichiers JS produits ;clean-css-brunchse base sur CleanCSS, un des meilleurs compacteurs CSS du marché (et si vous voulez intégrer le tout nouveau tout beau more-css, n’hésitez pas à contribuer un plugin !).- On trouve aussi
csso-brunch. uncss-brunchexploite le génial UnCSS pour détecter les parties « mortes » de nos feuilles de style ; si vous voulez combiner ça avec clean-css, vous avez soit les deux modules séparément, soit la comboclean-css-uncss-brunch.
On trouve également beaucoup de plugins visant à apposer une « empreinte » dans les noms de fichiers, afin de permettre des en-têtes de cache agressifs (expirations très lointaines).
digest-brunchcalcule l’empreinte en se basant sur le contenu ;git-digest-brunchethg-digest-brunchpréfèrent utiliser le SHA du commit courant (ce qui suppose que vous committez de façon appropriée).gzip-brunchcompresse les assets CSS/JS finalisés, en copie ou en remplacement des fichiers d’origine.
Si vous utilisez AppCache (et tant que vous n’avez pas ServiceWorker sous la main, vous devriez !), vous trouverez des trucs utiles aussi :
appcache-brunchmaintient tout seul le manifeste à jour, avec les noms des fichiers à cacher mais aussi un digest unique, auto-maintenu, qui fait que si un des fichiers cachés changent, le manifeste aussi ! Sans ça, invalider l’appcache en dev est vite pénible…- Dans le même esprit,
brunch-signaturecalcule un digest à partir des fichiers produits et le pose dans un fichier statique de votre choix ; ça vous permet par exemple de faire un poll Ajax à faible fréquence dessus pour détecter automatiquement, en cours de vie de la page, que l’appli a changé (et donc proposer un rechargement). - Toujours dans ce domaine-là,
version-brunchauto-maintient un numéro de version pour votre appli, basé sur celui de votrepackage.jsonmais avec un numéro de build en plus ; il le met aussi à dispo dans un fichier statique (que vous pouvez donc poller), et auto-remplace certains marqueurs de version dans tous vos fichiers produits.
Enfin, cloudfront-brunch est un des plugins capables d’auto-uploader vos assets dans un bucket S3, et d’envoyer la requête d’invalidation CloudFront pour vous. Sympa.
Réaliser un plugin Brunch
Histoire d’être à peu près complets, voyons maintenant comment faire nos propres plugins Brunch…
Brunch découpe ses plugins en plusieurs catégories : compilateurs, linters, optimiseurs… Suivant leur catégoriée détectée, ils sont consultés à divers moments du cycle de build, dans différents environnements, etc.
Une doc « API » est disponible en ligne, qui aide pas mal, et puis bien sûr on est libre de consulter le source des plugins existants. Mais pour vous mettre le pied à l’étrier, on va faire un plugin de type compilateur, qui sera générique quant aux extensions, toutefois.
Je vous ai parlé tout à l’heure du plugin git-digest-brunch, qui injecte dans les fichiers produits le SHA du HEAD à la place du marqueur ?DIGEST (il vise les URLs des assets). L’idée est de proposer une sorte de cache busting. Ce plugin n’intervient d’ailleurs qu’en mode production (ou plus exactement que lorsque le réglage optimize est actif).
Nous allons faire une variation de ça : un plugin qui remplace à la volée, au fil des compilations, un marqueur libre. Notre spécification fonctionnelle serait la suivante :
- Le marqueur est
!GIT-SHA!par défaut, mais la partie entre les points d’exclamation doit pouvoir être configurée viaplugins.gitSHA.marker. - La transformation se fait à tout moment, à la volée (builds one-shot ou watcher, production ou non).
- Tous les fichiers des répertoires surveillés (quels qu’ils soient) sont concernés, sauf les « purs statiques » (ceux qui sont dans un sous-dossier
assets). - Le marqueur comme les noms de dossiers surveillés doivent pouvoir contenir des caractères spéciaux d’expression rationnelle sans que cela pose problème.
Sur cette base, comment procéder ? Un plugin Brunch est avant tout un module Node, alors commençons par créer un dossier git-sha-plugin et déposons-y un package.json approprié :
{
"name": "git-sha-brunch",
"version": "1.7.0",
"private": true,
"peerDependencies": {
"brunch": "~1.7"
}
}
La partie peerDependencies n’est pas obligatoire (elle est même en phase de dépréciation), mais bon… En revanche, il est communément admis que les plugins Brunch suivent les numéros de versions majeur et mineur du Brunch à partir duquel ils sont compatibles. Donc si vous ne testez pas en-dessous de 1.7 par exemple, assurez-vous que votre version à vous démarre bien par 1.7. Remarquez que ça entre en conflit direct avec le semantic versioning (semver), du coup l’équipe de Brunch est en train de réfléchir à une meilleure manière d’exprimer la compatibilité entre le noyau et les plugins.
Comme on n’a pas précisé de champ main, Node supposera que notre point d’entrée est un fichier index.js. On sait qu’un plugin Brunch est un constructeur dont le prototype est doté de certaines propriétés, mentionnées plus haut dans cet article :
brunchPlugin, qui doit valoirtrue;type,extensionoupatternpour pouvoir être consulté au fil de la compilation ;compile(…),lint(…)ouoptimize(…), suivant le rôle ;onCompile(…)si on veut n’être notifié qu’en fin de build (même si c’est du watcher)teardown(…)si on doit faire du nettoyage lorsque Brunch s’arrête (par exemple arrêter un serveur qu’on aurait lancé dans le constructeur).
(En réalité, à part brunchPlugin, toutes les autres propriétés peuvent être définies dynamiquement sur l’instance produite par le constructeur, mais c’est rarement le cas, sauf pour pattern.)
Nous allons donc partir du squelette suivant :
"use strict";
// Marqueur par défaut. Peut être configuré via `plugins.gitSHA.marker`.
var DEFAULT_MARKER = 'GIT-SHA';
function GitShaPlugin(config) {
// 1. Construire le `pattern` en fonction de la config
// 2. Définir la regexp du marqueur en fonction de la config
}
// Indique à Brunch qu’on est bien un plugin
GitShaPlugin.prototype.brunchPlugin = true;
// Callback de compilation à la volée (fichier par fichier) ; suppose
// que Brunch a fait la correspondance avec notre `type`, `extension` ou
// `pattern`.
GitShaPlugin.prototype.compile = function processMarkers(params, callback) {
// Zéro transfo pour le moment
callback(null, params);
};
// Utilitaire : échappe tout caractère spécial de regex
function escapeRegex(str) {
return String(str).replace(/[-[\]{}()*+?.,\\^$|#\s]/g, '\\$&');
}
// Le plugin est l’export par défaut du module
module.exports = GitShaPlugin;
OK, commençons par le constructeur. On n’est pas spécialisés sur un type de fichier (scripts, styles ou templates), donc pas de propriété type sur notre prototype. Et on n’est pas limités à une extension, donc pas de propriété extension non plus. Il va nous falloir un pattern, qui est une expression rationnelle.
Comme celui-ci dépend des chemins, pas des extensions, il a besoin de la configuration, et sera créé dynamiquement à partir de ça. Le code sera celui-ci, au début du constructeur :
var pattern = config.paths.watched.map(escapeRegex).join('|')
pattern = '^(?:' + pattern + ')/(?!assets/).+'
this.pattern = new RegExp(pattern, 'i')Ainsi, les chemins par défaut (['app', 'vendor', 'test']) donneront l’expression suivante : /^(?:app|vendor|test)\/(?!assets\/).+/i.
À présent le marqueur. Le code sera un poil plus simple :
var marker = (config.plugins.gitSHA || {}).marker || DEFAULT_MARKER
this.marker = new RegExp('!' + escapeRegex(marker) + '!', 'g')On est sûrs que config.plugins existe, même s’il est un objet vide. Du coup sa propriété gitSHA pourrait être undefined d’où le || {} pour obtenir un objet vide dans ce cas. On y choppe marker, là aussi potentiellement undefined, ce qui nous amènerait de toutes façons à DEFAULT_MARKER. Mais si la clé de configuration est là, on prend.
Et on construit une bonne fois pour toutes la regexp correspondante.
À présent, chaque fois que compile(…) sera appelée (ce qui sous-entend qu’on est bien sur un fichier qui nous concerne, d’après notre pattern), il nous va falloir récupérer le SHA du HEAD Git en vigueur, et procéder au remplacement dans le contenu en mémoire pour le fichier.
On ne récupère pas le SHA une seule fois au démarrage, car il est fréquent qu’on committe au fil du dev, sans arrêter le watcher Brunch pour autant, et du coup la valeur deviendrait obsolète au fil du temps.
Cette récupération se fait en exécutant un git rev-parse --short HEAD en ligne de commande, ce qui, pour être propre et fidèle à l’esprit Node, est fait en asynchrone. On utilisera donc une fonction de rappel, en prenant soin de transmettre l’erreur éventuelle (genre, tu n’es pas dans un dépôt Git).
Voici notre petite fonction utilitaire :
function getSHA(callback) {
exec('git rev-parse --short HEAD', function (err, stdout) {
callback(err, err ? null : stdout.trim())
})
}Et maintenant, à nous la transformation à proprement parler :
GitShaPlugin.prototype.compile = function processMarkers(params, callback) {
var self = this
getSHA(function (err, sha) {
if (!err) {
params.data = params.data.replace(self.marker, sha)
}
callback(err, params)
})
}Et hop !
Pour tester notre plugin sans pourrir npm, nous allons faire ce qu’on appelle un npm link : l’installation en local d’un module en cours de développement.
Si vous avez récupéré le dépôt d’exemple, vous avez parmi les dossiers :
6-templates, le dernier où on ne jouait pas avec un serveur custom, et8-git-sha-plugin, qui contient le code ci-dessus, dûment commenté.
Voici comment faire :
- Allez dans
8-git-sha-plugindepuis la ligne de commande ; - Faites un
npm link: ça va enregistrer le dossier courant comme source des futursnpm link git-sha-plugin; - Allez dans
6-templatesdepuis la ligne de commande ; - Faites un
npm link git-sha-plugin: ça va vous l’installer (si on veut) en se basant sur le dossier source ; - Ajoutez tout de même (
npm linkne le fait pas) votre nouveau module local dans lepackage.json, sans oublier la virgule à la fin de la ligne précédente :
{
"name": "simple-brunch",
"version": "0.1.0",
"private": true,
"devDependencies": {
"brunch": "^1.7.20",
"jade-brunch": "^1.8.1",
"javascript-brunch": "^1.7.1",
"sass-brunch": "^1.8.9",
"git-sha-brunch": "^1.7.0"
}
}
```
Sans ça, Brunch ne le verra pas (il itère sur `package.json`, par sur le contenu de `node_modules`).
Si vous n'avez pas récupéré le dépôt par un `git clone`, vous n'êtes pas dans un dépôt Git. Si vous avez Git d'installé, voici comment obtenir un HEAD vite fait :
```bash
$ git init
Initialized empty Git repository in …/6-templates/.git/
$ git commit --allow-empty -m "Initial commit"
[master (root-commit) 8dfa8d9] Initial commit
```
(Bien évidemment, vous n'aurez pas le même SHA.)
Une fois prêts, ouvrez par exemple, dans ce même dossier, `app/application.js`, et rajoutez à un ou deux endroits un commentaire du style `// Version: !GIT-SHA!`. Sauvez. Lancez le build. Puis regardez le contenu du module en bas de `public/app.js` : le SHA a remplacé le marqueur. Vous pouvez essayez pendant que le *watcher* tourne, aussi : ça marche ! ᕙ(⇀‸↼‶)ᕗ
## En conclusion
Eh ben, il était **long** celui-là ! Dire qu’à la base je pensais m'en sortir en 5–6 heures… Mais comme j'arrêtais pas d'en rajouter au fil de l'eau, forcément.
J'éspère que **ça vous a plu**, et surtout que ça vous a **donné envie de tester Brunch** à la place de votre outil habituel, parce que la grande majorité du temps, ça sera **plus simple, plus rapide, en bref plus sympa !**
## Envie d'en savoir plus ?
On fait des formations JS magnifiques, qui font briller les yeux et frétiller les claviers :
* [JS Total](/fr/formations/web-app-modernes/), pour apprendre tout ce qu'il faut pour faire du dev web front moderne, efficace, rapide et haut de gamme.
* [Node.js](/fr/formations/node-js/), pour découvrir, apprivoiser puis maîtriser le nouveau chouchou de la couche serveur, qui envoie du gros pâté !