Workflow Git : objectifs et principes généraux
Par Maxime Bréhin • Publié le 2 octobre 2017
• 4 min
Choisir ou définir un workflow…
Quand on démarre avec Git, on commence toujours par la technique, les commandes, les subtilités techniques…
…Puis vient le moment du workflow. Celui où on essaie de mettre la méthodologie au propre, d’être cohérents sur la durée, de rationaliser tout ça. Et là, c’est un peu souvent le chantier. Git en soi est suffisamment flexible et ouvert pour ne pas imposer de workflow particulier, de sorte qu’on en trouve une pléthore, sans même parler des workflows « maison ».
Ainsi, en raison principalement de son antériorité, le Git Flow de Vincent Driessen est encore souvent sur le devant de la scène, même si, à l’usage, il s’avère souvent trop compliqué, avec des aspects contextuellement superflus. GitHub, GitLab et BitBucket, les 3 principaux éditeurs de solutions autour de Git, proposent tous peu ou prou la même approche : GitHub Flow, GitLab Flow, etc. qui se concentrent sur le recours aux pull/merge requests et la notion de feature branching, sans aller beaucoup plus loin (mais c’est déjà pas mal).
Nous avons donc décidé de pondre une petite série d’articles illustrant nos recommandations en matière de workflow de développement basé Git.
Dans cette série…
- Objectifs et principes généraux (cet article)
- Développer des fonctionnalités en parallèle
- Livrer et maintenir des versions publiques
- Corriger des bugs
- Définir les conventions d’un projet
Objectifs
On cherche à…
- faciliter le travail en équipe ;
- optimiser notre propre travail (bosser plus vite, sans gaspillage d’effort) ;
- gagner en qualité ;
- faire converger la gestion de projet et le développement.
En pratique, les besoins du workflow varieront d’un contexte projet à l’autre, en termes de complexité de la gestion projet et des ressources humaines. Les principales questions qui déterminent l’ampleur de nos besoins sont :
- Quel type de projet doit-on développer ? (logiciel avec releases, projet client « one shot »…)
- Dans quel laps de temps ?
- Quelles sont les technologies utilisées, quelle est l’architecture technique du projet ?
- Quel est le nombre d’intervenants ? Comment utilisent-ils Git ? (CLI, GUI, interfaces web…)
- Quelle est la méthodologie en place ? (Agile, Scrum, cycle en V…)
Par exemple, nul besoin d’un workflow complexe pour pondre un site institutionnel client mono-techno sur 1 mois à 3 intervenants (1 développeuse, 1 intégratrice, 1 chef de projet). C’est pourquoi tous les articles de cette série ne seront pas forcément pertinents pour tous les projets.
Principes généraux
Quel que soit le besoin, technique ou opérationnel, auquel on répondra à l’aide de Git, on veillera toujours à respecter quelques principes fondateurs, qui vont orienter le détail de nos manipulations.
Vous pouvez tout à fait opter pour une mise en place progressive de ces savoirs et approches : une bascule brutale de méthodologie n’est pas toujours aisée ni pertinente…
1. Produire un historique clair
Aussi bête que cela paraisse, il n’est pas facile de produire un historique clair. La principale difficulté est d’encourager les membres d’une équipe à produire des commits dits atomiques. Ce terme vise à exprimer qu’un commit doit contenir un ensemble de travail cohérent et exploitable.
Pour cela il faut respecter certaines règles élémentaires :
- découper les tâches les plus fines possible sans entremêler des sujets et faire de chacune un commit;
- nommer ce travail de la manière la plus concise possible en une ligne, complétée éventuellement d’une description plus exhaustive (lignes suivantes).
Les commits produits doivent pouvoir être analysés et exploités par nos collègues (ou vous même dans 3 mois). Ils devront pouvoir être extraits pour être appliqués sur un autre projet ou un autre endroit de notre projet (ex : report de correctif de bug).
Pour faciliter la mise en place de règles spécifiques ou conventions de nommage des commits au sein d’une équipe, on trouve des solutions d’aide à la saisie telles que commitizen, exploitable avec des conventions pré-établies comme le conventional changelog.
Ainsi on réduit le facteur d’erreur lié à une saisie 100% manuelle.
2. Isoler les lots de développements
Nous pouvons étendre nos conventions pour modéliser les sous-ensembles thématiques/fonctionnels sous forme de branches.
On isole leur développement en créant une branche pour chaque lot. Nos conventions décriront l’organisation des branches tout comme leurs noms.
Les avantages sont alors multiples :
- On améliore la lecture de l’historique ;
- On parallélise les développements des lots fonctionnels ;
- On facilite les processus de qualité en encourageant des validations lors des fusions/fermetures de branches.
3. Refléter la méthodologie du projet
Il peut s’avérer très utile de retranscrire notre méthodologie projet au sein de notre schéma de branche.
Prenons l’exemple de Scrum
Dans notre équipe, nous considérons que chaque epopée/epic représente un ensemble fonctionnel livrable.
Ces épopées sont ensuite découpées en sprints successifs, eux mêmes découpés en user stories.
La retranscription au sein de notre schéma de branches pourrait être la suivante :
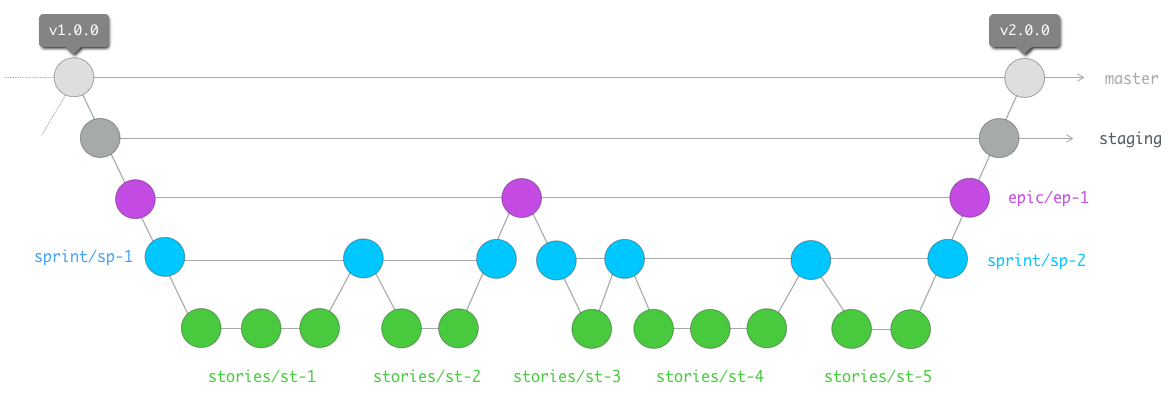
Un avantage certain de ce type de pratique est la facilité de lecture des avancées sur le projet pour des personnes n’ayant aucun bagage technique. On permet donc a des responsable fonctionnels ou managers de suivre un projet et des équipes par la simple consultation d’un graphe de branches.
4. Améliorer la qualité en exploitant au mieux les tests
Cette approche d’isolement fonctionnel est utile, mais nous pouvons améliorer ce mécanisme en essayant de garantir que le travail fusionné sur notre branche « stable » sera le plus qualitatif possible.
Pour cela nous pouvons effectuer des opérations manuelles et/ou automatiques.
Une approche popularisée par GitHub et présente dans la plupart des interfaces utilisateurs basées Git est celle des pull requests, également appelées merge requests :
Chaque branche terminée et prête à être fusionnée fait l’objet d’une demande de fusion. Cette demande peut être accompagnée d’un commentaire et peut donner lieu à :
- des discussions;
- des revues de code (avec validation/invalidation pouvant nécessiter du travail supplémentaire);
- des automatisations, telles que le lancement automatique des tests d’intégration (Intégration Continue) qui peuvent interdire la fusion dans l’interface s’ils détectent le moindre problème;
- des restrictions, en mettant en place une gestion des droits par projet ou par branche.
L’intérêt est d’assurer une certaine qualité au travail fusionné en effectuant des revues de code, des validations techniques ou fonctionnelles (non limitées à des développeurs/techniciens), des verrous, des commentaires, des remontées de bugs… Bref, tout ce qu’on peut imaginer pour nos projets dans un processus de qualité !
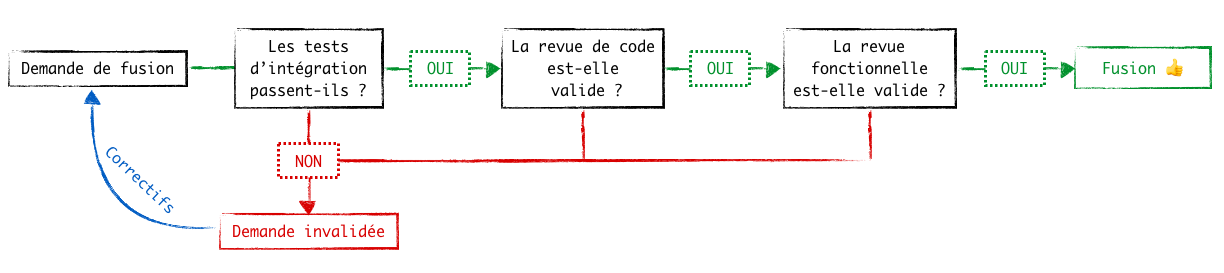
Note : si vous ne pouvez bénéficier d’une interface graphique côté serveur, sachez que vous n’êtes pas dépourvu d’outils pour effectuer ce type d’opération. Vous pouvez par exemple écrire vous même vos scripts pour les traitements automatiques grâces aux hooks. C’est plus compliqué, mais pas insurmontable !
Et maintenant ?
Allez explorer nos recommandations détaillées par type de besoin !
- Objectifs et principes généraux (cet article)
- Développer des fonctionnalités en parallèle
- Livrer et maintenir des versions publiques
- Corriger des bugs
- Définir les conventions d’un projet