Git add hero 🤘
Par Maxime Bréhin • Publié le 12 janvier 2022
• 7 min
Lorsqu’on débute avec Git, une des premières commandes qu’on utilise est git add. Elle est essentielle à une bonne utilisation de Git puisqu’elle nous permet de préparer nos commits. Elle n’est pourtant jamais vraiment apprise, ce qui est regrettable car elle nous offre des options très pratiques !
Pour bien comprendre cet article, il est important d’avoir déjà assimilé la notion de zones Git. Et comme on aime faire les choses bien, on a écrit un article à ce sujet.
Vous préférez une vidéo ?
Si vous êtes du genre à préférer regarder que lire pour apprendre, on a pensé à vous :
Principe de fonctionnement
Lorsqu’on fait un git add … on demande à Git d’enregistrer dans le stage les fichiers qu’on souhaitera plus tard valider (intégration au commit). En d’autres termes, on ajoute, modifie, supprime des fichiers dans notre copie de travail et on signale à Git que tout ou partie de ces modifications est à mettre dans un statut intermédiaire (staged) avant d’être validé sous la forme d’un commit.
On a donc la possibilité de préciser des chemins complets ou partiels (globs) et ne prendre qu’une partie des modifications réalisées dans notre copie de travail (working directory) en vue d’un commit prochain.
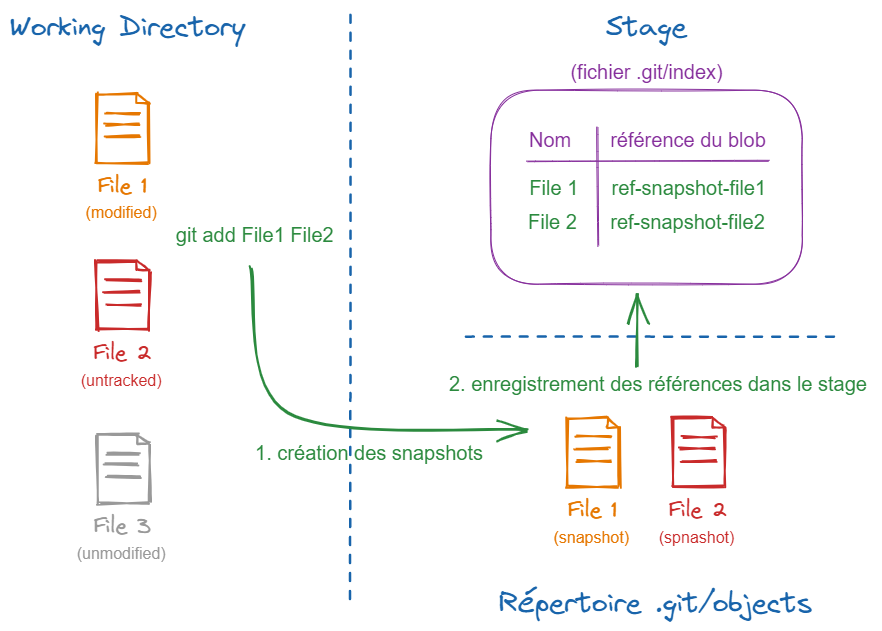
Si la technique vous intéresse, voici ce qui se passe sous le capot :
- Pour chaque fichier, un « instantané » du contenu est capturé :
- il ne stocke pas les différences mais bien l’intégralité du fichier dans sa nouvelle version ;
- ce fichier est optimisé pour stockage sur le disque et appelé blob (pour Binary Large Object) ;
- le nom de ce fichier est une empreinte basée sur le contenu du fichier (hash de type SHA-1 ou SHA-2) ;
- ce fichier est stocké dans le répertoire
.git/objects.
- Les références aux fichiers sont enregistrées dans le stage (fichier
.git/index).
Utilisation « classique »
Que vous soyez dans un terminal ou dans un éditeur muni d’une interface Git, vous aurez accès aux utilisations les plus fréquentes de la commande add, à savoir l’enregistrement des ajouts, modifications et suppressions des fichiers complets. Ceci équivaut en ligne de commande à passer le ou les chemins de fichiers concernés :
git add file-1 file-2On peut aller bien plus loin et gagner en temps, en confort, en qualité en s’aidant de quelques options. Remarquez que certaines options ne sont parfois disponibles qu’en ligne de commande. À vous de déterminer si votre éditeur préféré sait gérer celles qui vous intéressent.
Notre sélection d’options utiles
<chemins>(ou-- <chemins>pour lever l’ambiguïté avec le double tiret POSIX) ;-u/--update, pour ne traiter que les fichiers déjà versionnés ;-A/--all/--no-ignore-removal, la totale : ajouts, modifications, suppressions ;-f/--forcepour forcer l’ajout de fichiers normalement ignorés ;-p/--patch, pour ne stager qu’une partie des modifications des fichiers ;-N/--intent-to-addpour permettre les diffs, leadd -pet lecommit -ades fichiers non-suivis.
Un petit tour des globs
Les (nombreuses) commandes Git capables de travailler avec des chemins de fichiers vous offrent la possibilité (en ligne de commande notamment) de passer des chemins exacts (fichiers ou répertoires) voire des globs. Faisons un petit tour d’horizon de ces usages :
# Fichiers
git add file-1 file-2 director-1/file-3
# Répertoires
git add director-1/ directory-2/sub-directory
# Le célèbre « prend tout dans le dossier courant »
git add .
# Les globs ou motifs de chemins (ici : tous les fichiers dans le
# répertoire courant dont le nom commence par « file » et tous les
# fichiers dans tous les sous-répertoires ayant pour extension « .js »)
git add file* **/*.js
# Et bien évidemment on peut mélanger les syntaxes
git add file-1 dir-1/ *.mdCes syntaxes sont utilisables pour la partie fichiers de l’appel, qui suit les options de git add.
Tout sauf les nouveautés
Vous souhaiterez parfois n’intégrer que les modifications et suppressions, donc tout sauf les fichiers nouvellement créés (qui ne sont pas encore versionnés). Pour ça, vous avez l’option -u / --update :
Tout, partout !
Vous voudrez souvent prendre l’intégralité du travail en cours : ajouts, suppressions et modifications. On utilise en général git add ., mais si vous avez tendance à vous balader dans vos répertoires, ce . ne désignant que le répertoire courant et ses sous-répertoires, vous pourriez manquer les répertoires parents.
C’est là tout l’intérêt d’employer plutôt git add --all / -A :
Cesse de m’ignorer !
Si les fichiers que vous souhaitez ajouter font partie des fichiers habituellement ignorés par Git (voir le fonctionnement du .gitignore), vous devrez alors forcer leur ajout avec l’option --force / -f. Une fois ces fichiers versionnés, leurs modifications ultérieures apparaitront au même titre que pour les autres fichiers. Pour cesser de les versionner tout en les conservant sur disque, vous aurez besoin d’un git rm --cached par exemple (notez qu’ils existeront toujours dans les commits qui les contenaient).
Pour illustrer cela, prenons le cas de figure récurrent des logs. Généralement les fichiers de logs sont placés dans un répertoire applicatif dédié, ici log/, et on ne souhaite pas historiser les logs dans Git, ça n’a aucun intérêt. On va alors indiquer dans le fichier .gitignore qu’on ne souhaite pas versionner les fichiers contenus dans ce répertoire :
# On recourt à une astuce pour ajouter rapidement
# en fin de fichier la ligne « log/* ».
echo 'log/*' >> .gitignoreSi votre stack technique ne crée pas automatiquement son dossier de logs (et refuse de se lancer s’il n’existe pas), vous devrez vous assurer qu’il existe d’office, ce qui suppose que Git versionne le répertoire. Sauf que Git ne gère pas des répertoires, seulement des fichiers. Pour palier à ça, l’astuce classique consiste à créer un fichier vide .keep ou .git-keep dans le répertoire ciblé :
# Crée un fichier vide « .keep » dans le répertoire « log ».
touch log/.keepLe problème, c’est que ce fichier est ignoré, il ne nous est pas proposé à l’ajout lors d’un git status et git add refusera de l’ajouter — mais nous dira que nous pouvons forcer l’ajout :
git add --force log/.keepEt voilà, le tour est joué !
L’ajout chirurgical : « Docteur Patch »
S’il y a une option qu’on affectionne particulièrement, c’est bien le git add --patch ! Elle nous permet de choisir, au sein d’un fichier, les modifications qu’on souhaite stager. C’est parfait quand on s’aperçoit qu’on a travaillé sur plusieurs aspects et qu’on souhaite découper tout ça pour obtenir plus de clarté dans notre historique de commits.
Si on l’utilise sans paramètre supplémentaire, les fichiers nous seront proposés un à un avec un éventuel pré-découpage des fragments de modifications (appelés hunks) quand l’espacement entre ces blocs est assez conséquent.
On peut là aussi passer des chemins ou globs pour ne proposer des découpes que sur les fichiers qui nous intéressent.
Lorsqu’on a lancé la commande, un assistant s’ouvre et affiche ce qui ressemble à un git diff. Cet affichage nous indique le nombre de fragments qu’il a découpés dans le fichier (dans l’exemple qui suit (1/2) signifie qu’on traite le premier bloc sur 2). Il nous pose ensuite une question avec tout plein de lettres entre crochets derrière, qui n’est pas le truc le plus clair du monde :
(1/2) Stage this hunk [y,n,q,a,d,j,J,g,/,e,?]?
Heureusement, on peut renseigner le point d’interrogation ? puis valider pour obtenir davantage de précisions :
y - stage this hunk
n - do not stage this hunk
q - quit; do not stage this hunk or any of the remaining ones
a - stage this hunk and all later hunks in the file
d - do not stage this hunk or any of the later hunks in the file
g - select a hunk to go to
/ - search for a hunk matching the given regex
j - leave this hunk undecided, see next undecided hunk
J - leave this hunk undecided, see next hunk
s - split the current hunk into smaller hunks
e - manually edit the current hunk
? - print help
Notez que l’option s (split) n’est disponible que lorsque le fragment affiché permet d’être redécoupé facilement (quand il existe des lignes intactes entre les modifications du fragment courant).
Pour un usage courant, on utilisera principalement les options y (pour valider le fragment) et n (pour l’inverse). Parfois le s quand la découpe n’est pas assez fine à notre goût.
Il existe également une option e (edit) pour permettre la modification manuelle du fragment, ce qui revient à gérer à la main les + et - d’un diff. C’est tentant si on se trouve face à un fragment sans séparation, donc sans option s disponible, et qu’on souhaite découper quand même. Attention tout de même, il est difficile de construire manuellement un fragment approprié, et ça donne souvent des résultats inattendus. Mieux vaut alors reprendre votre fichier, retirer temporairement la partie du fragment que vous ne souhaitez pas ajouter, faire votre git add … puis remettre la portion retirée dans le fichier.
Voici un exemple d’utilisation qui produit 3 commits à partir d’un unique fichier modifié en plusieurs endroits, chaque commit étant dédié à un sujet précis.
L’intention d’ajout
C’est l’ajout indécis, « à la normande » : je veux ajouter, mais pas vraiment ! 😵 ??
Il s’agit ici de l’option --intent-to-add ou -N.
Elle s’avère pratique lorsqu’on souhaite visualiser l’ensemble des différences stagées, y compris les nouveaux fichiers. En d’autres termes : sans ajout ou intention d’ajout, la commande git diff ne nous permettra pas de voir le contenus des nouveaux fichiers. Même chose d’ailleurs pour le git add -p.
D’autre part elle permet la prise en considération des nouveaux fichiers (non suivi/untracked) en cas d’utilisation du raccourci de commande git commit -a … (qui équivaut à un git add -u + git commit).
L’ajout interactif, la fausse bonne idée
Si vous avez ouvert un jour la documentation de git add (pour les curieux·ses : git help add), peut-être avez vous découvert l’option -i / --interactive. Peut-être même avez-vous osé ouvrir cette boite de Pandore et découvert le démon qui s’y cachait 👿.
Contrairement à ce qu’on pourrait croire d’elle, cette option ne nous simplifie pas la tâche d’ajout en nous fournissant une interface sensationnelle. Bien au contraire, elle nous plonge dans une interface particulièrement déroutante.
Une petite démo vaut mieux que des mots :
Bien préparer ses commits
Vous l’aurez compris, la commande git add ne nous contraint pas à un simple ajout en masse des modifications, et c’est tant mieux ! Cela nous permet de préparer au mieux des commits atomiques 🤯, c’est-à-dire traitant d’un sujet le plus précisemment possible, et, par conséquent, de produire un historique clair et utile.
Si vous voulez creuser plus ce sujet, nous vous recommandons de parcourir notre série d’articles sur l’utilisation de Git pour assister et automatiser la qualité des commits dans nos projets.